
https://www.kaggle.com/datasets/hmavrodiev/london-bike-sharing-dataset
London bike sharing dataset
Historical data for bike sharing in London 'Powered by TfL Open Data'
www.kaggle.com
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
df = pd.read_csv('/kaggle/input/london-bike-sharing-dataset/london_merged.csv', parse_dates = ['timestamp'])
df.head()
df['timestamp']
df.shape
train = df.iloc[:17000, 1:2]
test = df.iloc[17000:17414, 1:2]
print(train.shape)
print(test.shape)
df['cnt'][:17000].plot(figsize = (15, 4), legend = True)
df['cnt'][17000:].plot(figsize = (15, 4), legend = True)
plt.legend(['train', 'test'])
plt.title('bike share demand')
plt.show()
from statsmodels.tsa.stattools import pacf
pacf = pacf(df['cnt'], nlags = 20, method = 'ols')
print(pacf)
from statsmodels.graphics.tsaplots import plot_pacf
plot_pacf(pacf, lags = 8, method = 'ols', title = 'pa').show
from sklearn.preprocessing import MinMaxScaler
sc = MinMaxScaler(feature_range = (0, 1))
train_scaled = sc.fit_transform(train)
train_scaled
X_train = []
y_train = []
for i in range(1, 17000):
X_train.append(train_scaled[i-1:i, 0])
y_train.append(train_scaled[i, 0])
X_train, y_train = np.array(X_train), np.array(y_train)
print(X_train.shape)
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
print(X_train.shape)
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import SimpleRNN
rnn = Sequential()
rnn.add(SimpleRNN(activation = 'relu', units = 6, input_shape = (1, 1)))
rnn.add(Dense(activation = 'linear', units = 1))
print(rnn.summary())
rnn.compile(loss = 'mse', optimizer = 'adam', metrics = ['mse'])
rnn.fit(X_train, y_train, batch_size = 1, epochs = 2)
inputs = sc.transform(test)
inputs.shape
X_test = []
for i in range(1, 415):
X_test.append(inputs[i-1:i,0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
rnn = rnn.predict(X_test)
rnn = sc.inverse_transform(rnn)
test1 = pd.DataFrame(test)
rnn1 = pd.DataFrame(rnn)
print(test1.shape)
print(rnn1.shape)
test1.plot(figsize = (15, 4), legend = True)
plt.legend(['cnt'])
plt.title('bike share demand')
plt.show()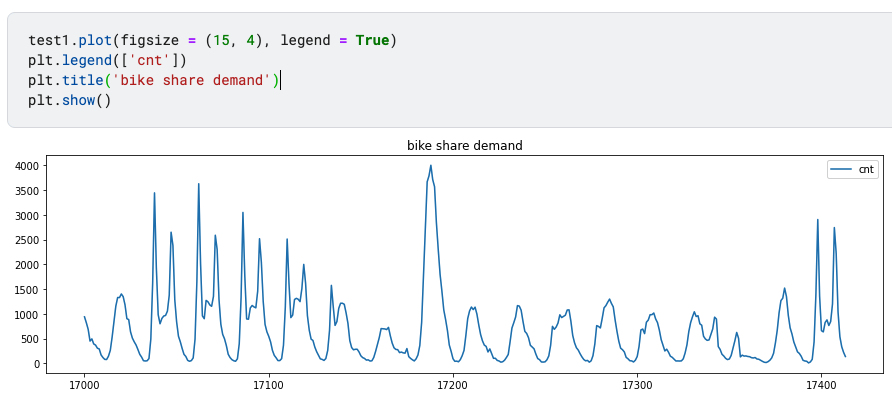
rnn1.plot(figsize = (15, 4), legend = True)
plt.legend(['rnn'])
plt.title('bike share demand')
plt.show()
test = np.array(test)
test.shape
plt.figure(figsize = (15, 5))
plt.plot(test, marker='.', label='cnt', color='black')
plt.plot(rnn, marker=',', label='RNN', color='red')
plt.legend()
# LSTM
from keras.layers.recurrent import LSTM
lstm = Sequential()
lstm.add(LSTM(units = 6, activation = 'relu', input_shape = (1, 1)))
lstm.add(Dense(units = 1, activation = 'linear'))
print(lstm.summary())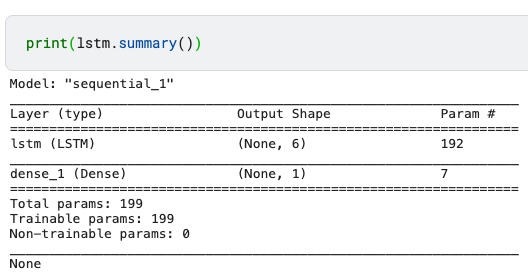
lstm.compile(loss = 'mse', optimizer = 'adam', metrics = ['mse'])
lstm.fit(X_train, y_train, batch_size = 1, epochs = 2)
lstm = lstm.predict(X_test)
lstm = sc.inverse_transform(lstm)
plt.figure(figsize = (15, 5))
plt.plot(test, marker='.', label='cnt', color='black')
plt.plot(lstm, marker=',', label='LSTM', color='green')
plt.legend()
'Programming Language > Python' 카테고리의 다른 글
| [Python] 해당 날짜가 주식 개장일인지 확인하는 방법 (0) | 2022.05.21 |
|---|---|
| [Python] UserWarning: Workbook contains no default style, apply openpyxl's default warn("Workbook contains no default style, apply openpyxl's default") (0) | 2022.05.21 |
| [Kaggle] 런던 자전거 데이터 세트, 시계열 딥러닝 전 데이터 전처리 정리 (0) | 2022.05.13 |
| [Kaggle] 런던 자전거 데이터 세트, 시계열 딥러닝 전 데이터 전처리해보기 (0) | 2022.05.13 |
| [Kaggle] 런던자전거 - 머신러닝, 딥러닝 모델 비교해보기 (0) | 2022.05.11 |