from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
spark = SparkSession \
.builder \
.master('local') \
.appName('my_pyspark_app') \
.getOrCreate()
data = [
('kim', 100),
('kim', 90),
('lee', 80),
('lee', 70),
('park', 60)
]
schema = ['name', 'score']
df = spark.createDataFrame(data = data, schema = schema)
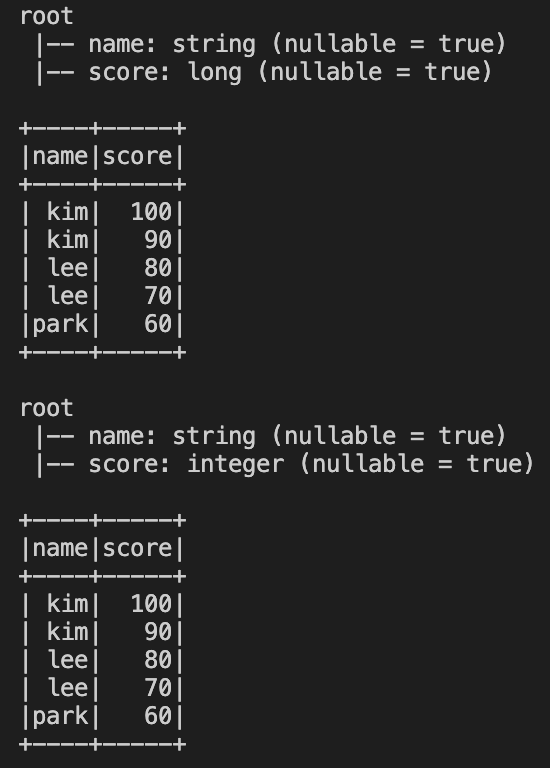
df.printSchema()
df.show()
data = [
('kim', 100),
('kim', 90),
('lee', 80),
('lee', 70),
('park', 60)
]
schema = StructType([
StructField('name', StringType(), True),
StructField('score', IntegerType(), True)
])
df = spark.createDataFrame(data = data, schema = schema)
df.printSchema()
df.show()