
https://www.kaggle.com/datasets/hmavrodiev/london-bike-sharing-dataset
London bike sharing dataset
Historical data for bike sharing in London 'Powered by TfL Open Data'
www.kaggle.com
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))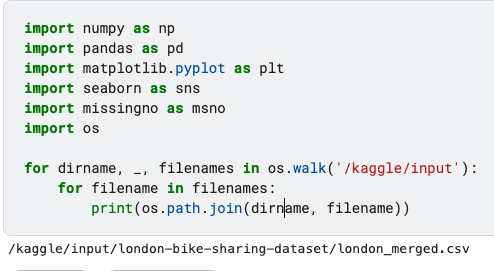
df = pd.read_csv('/kaggle/input/london-bike-sharing-dataset/london_merged.csv', parse_dates = ['timestamp'])
# df = pd.read_csv('/kaggle/input/london-bike-sharing-dataset/london_merged.csv')
df.head()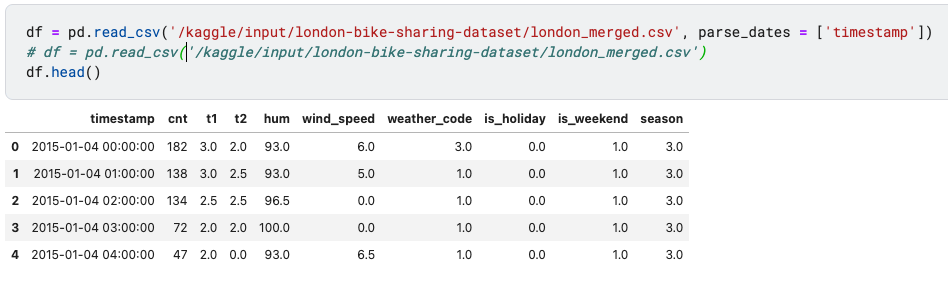
print('< 데이터 구조 >\n', df.shape)
print('< 데이터 타입 >\n', df.dtypes)
print('< 데이터 컬럼 >\n', df.columns)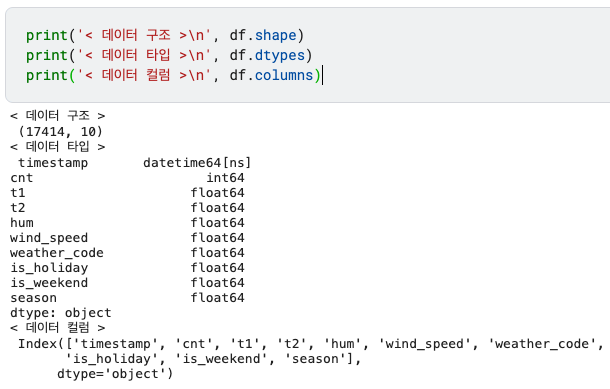
print('< 결측치 >')
df.isna().sum()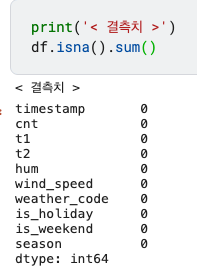
print('< 결측치 시각화 >')
msno.matrix(df)
plt.show()
df['year'] = df['timestamp'].dt.year
df['month'] = df['timestamp'].dt.month
df['dayofweek'] = df['timestamp'].dt.dayofweek
df['hour'] = df['timestamp'].dt.hour
df.head()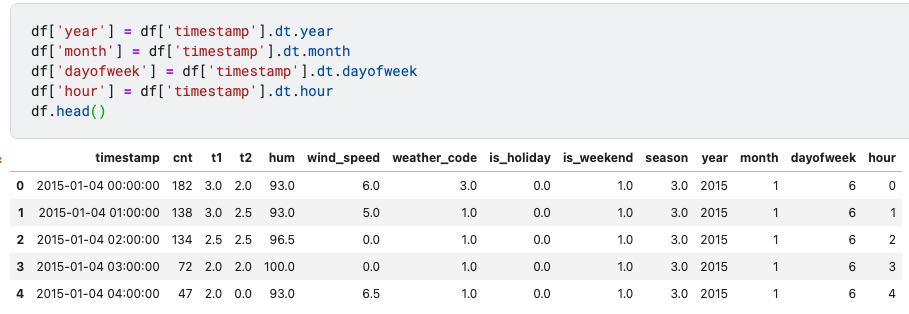
df['year'].value_counts()
# df['month'].value_counts()
# df['dayofweek'].value_counts()
# df['weather_code'].value_counts()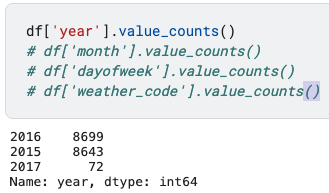
a, b = plt.subplots(1, 1, figsize=(10, 5))
sns.boxplot(df['year'], df['cnt'])
# sns.boxplot(df['month'], df['cnt'])
# sns.boxplot(df['dayofweek'], df['cnt'])
# sns.boxplot(df['hour'], df['cnt'])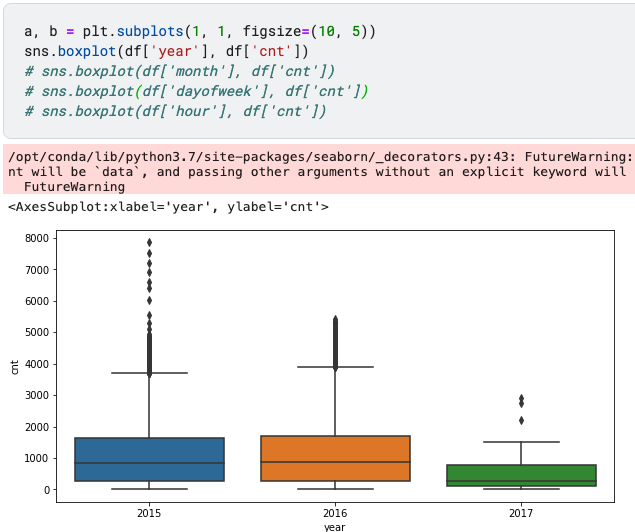
def plot_bar(data, feature):
fig = plt.figure(figsize = (12, 3))
sns.barplot(x = feature, y = 'cnt', data = data, palette = 'Set3')
plot_bar(df, 'hour')
# plot_bar(df, 'dayofweek')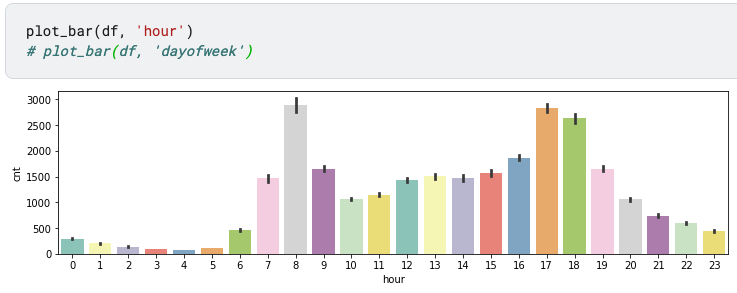
def is_outliers(s):
lower_limit = s.mean() - (s.std() * 3)
upper_limit = s.mean() + (s.std() * 3)
return ~s.between(lower_limit, upper_limit)
df_out = df[~df.groupby('hour')['cnt'].apply(is_outliers)]
print('이상치 제거 전 :', df.shape)
print('이상치 제거 후 :', df_out.shape)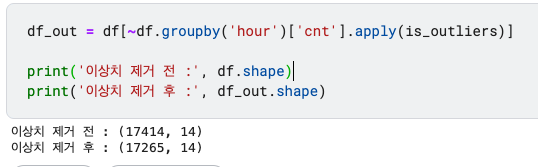
df_out.dtypes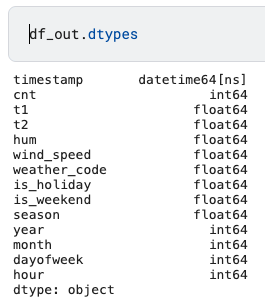
df_out['weather_code'] = df_out['weather_code'].astype('category')
df_out['season'] = df_out['season'].astype('category')
df_out['year'] = df_out['year'].astype('category')
df_out['month'] = df_out['month'].astype('category')
df_out['hour'] = df_out['hour'].astype('category')
df_out.dtypes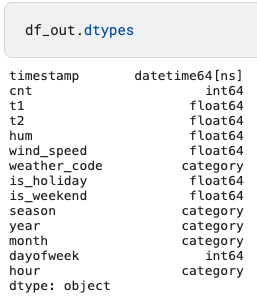
df_out['season']
df_out = pd.get_dummies(df_out, columns=['weather_code', 'season', 'year', 'month', 'hour'])
df_out.head()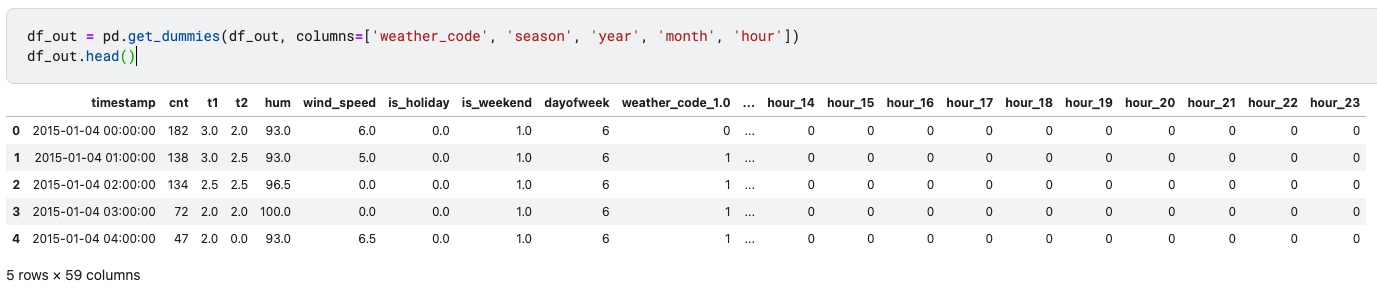
df_out.shape
df_y = df_out['cnt']
df_x = df_out.drop(['timestamp', 'cnt'], axis = 1)
df_x.head()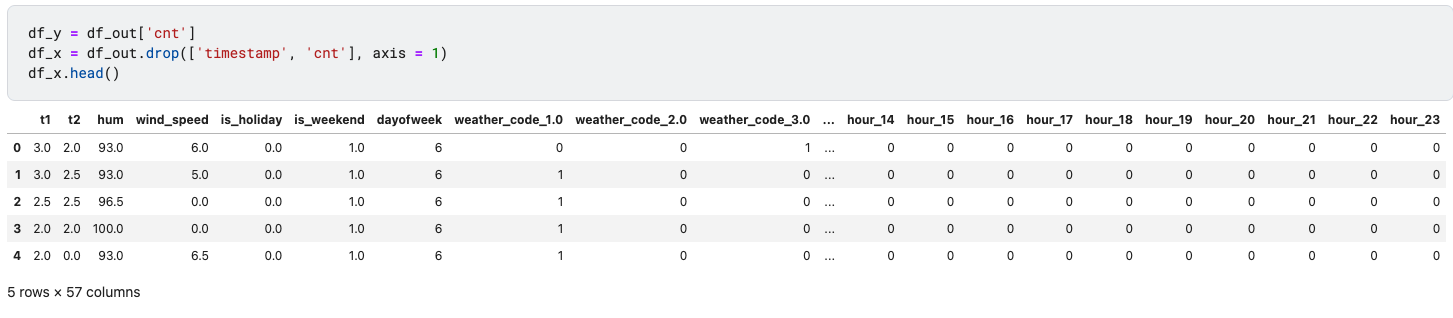
df_y.head()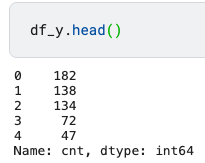
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(df_x, df_y, random_state = 1004, test_size = 0.3, shuffle = False)
print('x_train의 구조 :', x_train.shape)
print('y_train의 구조 :', y_train.shape)
print('x_test의 구조 :', x_test.shape)
print('y_test의 구조 :', y_test.shape)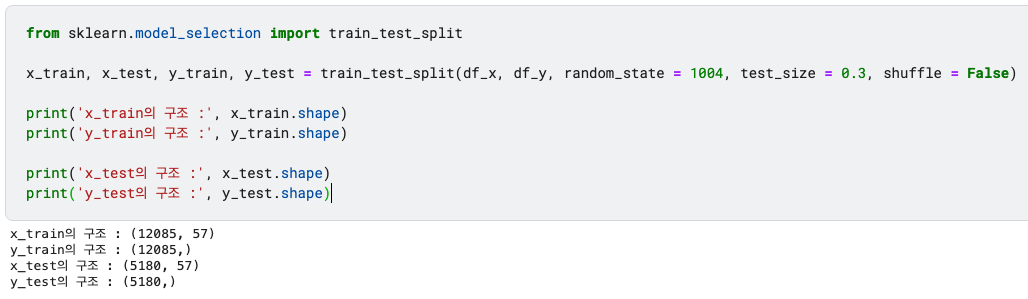
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import EarlyStopping
model = Sequential()
model.add(Dense(units = 160, activation = 'relu', input_dim = 57))
model.add(Dense(units = 60, activation = 'relu'))
model.add(Dense(units = 20, activation = 'relu'))
model.add(Dense(units = 1, activation = 'linear'))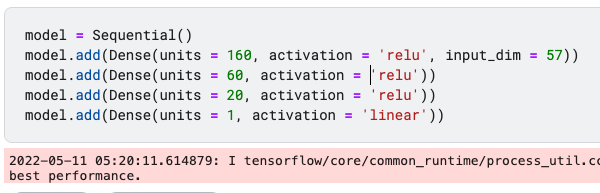
model.summary()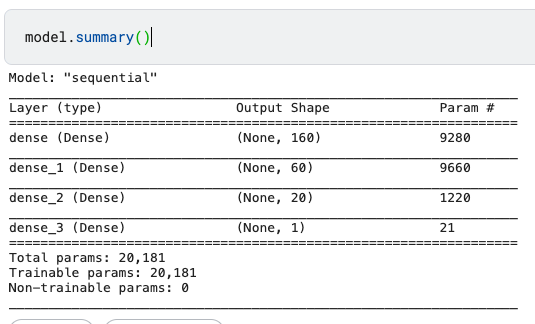
model.compile(loss = 'mae', optimizer = 'adam', metrics = ['mae'])
early_stopping = EarlyStopping(monitor = 'loss', patience = 5, mode = 'min')
history = model.fit(x_train, y_train, epochs = 50, batch_size = 1, validation_split = 0.1, callbacks = [early_stopping])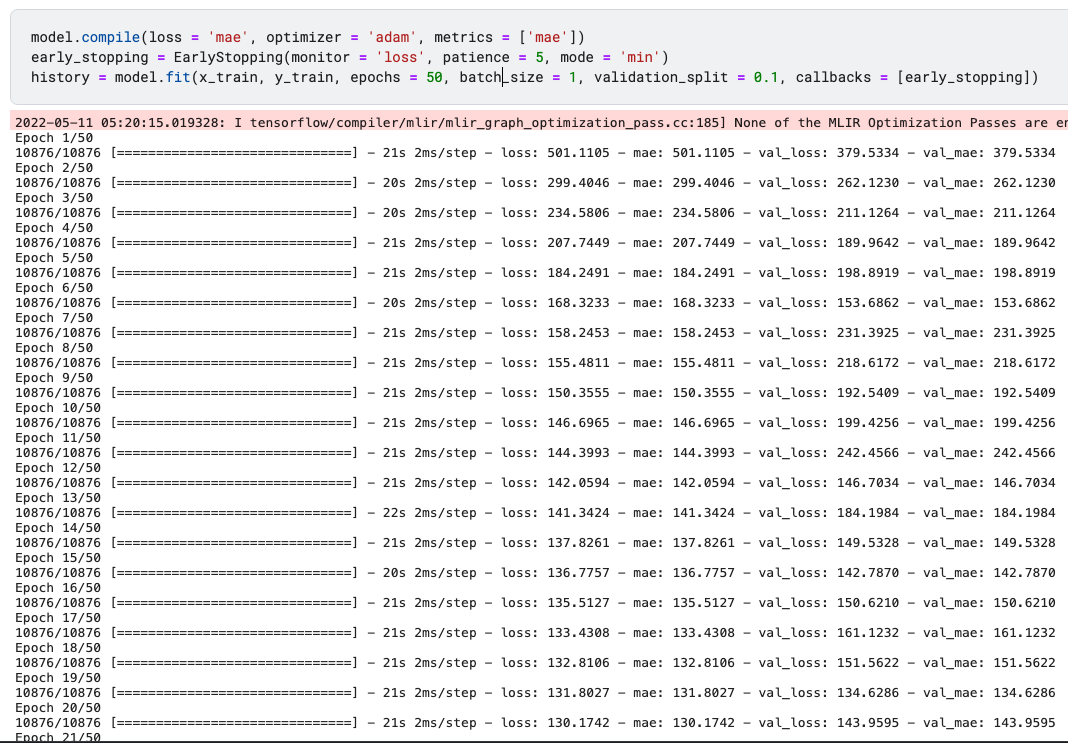
plt.plot(history.history['val_loss'])
plt.plot(history.history['loss'])
plt.title('loss')
plt.xlabel('Epochs')
plt.ylabel('loss')
plt.legend(['val_loss', 'loss'])
plt.show()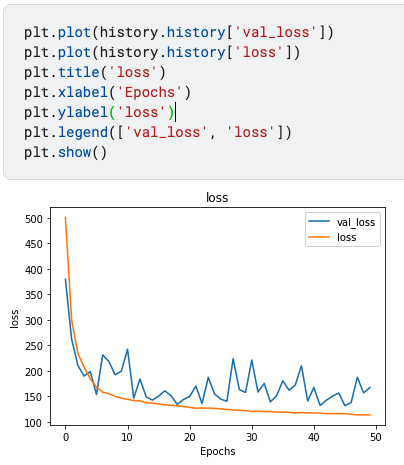
y_predict = model.predict(x_test)
from sklearn.metrics import mean_squared_error
def RMSE(y_test, y_predict):
return np.sqrt(mean_squared_error(y_test, y_predict))
print('RMSE :', RMSE(y_test, y_predict))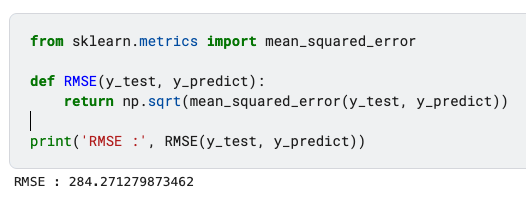
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor(n_estimators = 100, random_state = 1004)
rf.fit(x_train, y_train)
rf_result = rf.predict(x_test)
print('RMSE', RMSE(y_test, rf_result))
from xgboost import XGBRegressor
xgb = XGBRegressor(n_estimators = 100, random_state = 1004)
xgb.fit(x_train, y_train)
xgb_result = xgb.predict(x_test)
print('RMSE', RMSE(y_test, xgb_result))
from lightgbm import LGBMRegressor
lgb = LGBMRegressor(n_estimators = 100, random_state = 1004)
lgb.fit(x_train, y_train)
lgb_result = lgb.predict(x_test)
print('RMSE', RMSE(y_test, lgb_result))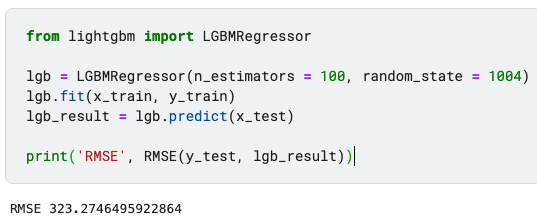
dnn = pd.DataFrame(y_predict)
rf = pd.DataFrame(rf_result)
xgb = pd.DataFrame(xgb_result)
lgb = pd.DataFrame(lgb_result)
compare = pd.DataFrame(y_test).reset_index(drop = True)
compare['dnn'] = dnn
compare['rf'] = rf
compare['xgb'] = xgb
compare['lgb'] = lgb
compare.head()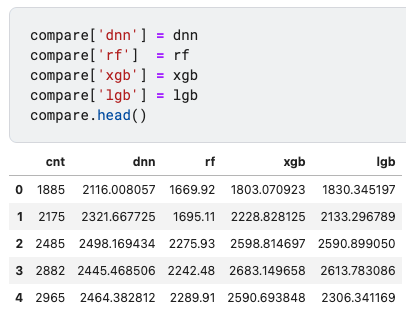
sns.kdeplot(compare['cnt'], shade = True, color = 'red')
sns.kdeplot(compare['dnn'], shade = True, color = 'green')
sns.kdeplot(compare['rf'], shade = True, color = 'blue')
sns.kdeplot(compare['xgb'], shade = True, color = 'yellow')
sns.kdeplot(compare['lgb'], shade = True, color = 'orange')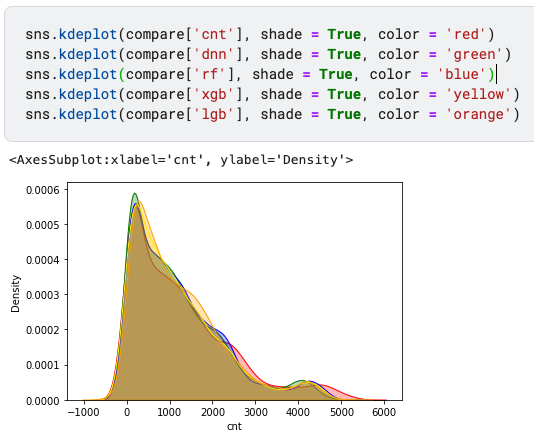
'Programming Language > Python' 카테고리의 다른 글
| [Kaggle] 런던 자전거 데이터 세트, 시계열 딥러닝 전 데이터 전처리 정리 (0) | 2022.05.13 |
|---|---|
| [Kaggle] 런던 자전거 데이터 세트, 시계열 딥러닝 전 데이터 전처리해보기 (0) | 2022.05.13 |
| [Kaggle] London Bike Sharing Dataset 딥러닝 모델 만들어보기 (0) | 2022.05.08 |
| [Kaggle] London Bike Sharing Dataset 데이터 전처리 해보기 (0) | 2022.05.08 |
| [Python] 데이터프레임의 구조, 타입, 컬럼 확인하는 방법 (0) | 2022.05.04 |