
P-Value 개념
P-Value는 고전적 빈도주의(Frequentist) 통계학에서 가설 검정을 수행할 때 사용되는 핵심적인 개념임.
주어진 데이터와 통계적 모델(특히 귀무 가설 H0)이 있을 때, 데이터가 귀무 가설과 얼마나 양립하기 어려운지를 수치로 표현한 것이 바로 P-Value임.
P-Value의 정의 및 직관
1. 공식적 정의
P-Value는 귀무 가설이 참이라고 가정했을 때, 우리가 관찰한 통계량(또는 그보다 더 극단적인 통계량)이 나올 확률임.
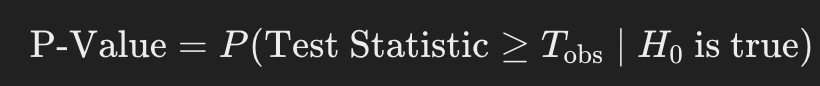
여기서 Tobs는 실제 실험(또는 표본)에서 얻은 테스트 통계량(observed test statistic)을 의미함.
2. 직관적 이해
P-Value가 작다는 것은, “귀무 가설이 참이라고 하면 이런 데이터(또는 더 극단적인 데이터)가 나올 가능성이 매우 작다”를 의미함.
P-Value가 크다는 것은, “귀무 가설하에서도 충분히 이런 데이터가 관측될 수 있다”를 뜻함.
3. “극단적”이라는 표현의 의미
“극단적”이란 용어는 실험 목적과 검정 통계량의 정의에 따라 달라짐.
예를 들어 양측 검정에서 “극단적”은 관찰값이 양쪽 꼬리에서 더 먼 경우를 의미할 수 있고, 단측 검정에서는 한쪽 방향으로 먼 경우를 의미함.
가설 검정에서의 P-Value의 역할
1. 귀무 가설(H0)와 대립 가설(H1)
귀무 가설: “실제로 효과가 없다”, “두 집단 간 차이가 없다” 등 연구에서 ‘기본 가정’ 혹은 “변화 없음”을 표현함.
대립 가설: 귀무 가설의 반대 개념으로, “효과가 있다”, “두 집단 간 차이가 있다”와 같은 현상.
2. 유의수준(α)
연구자가 미리 정하는 임계값(예: 0.05, 0.01, 0.001 등).
P-Value ≤ α 일 경우, 귀무 가설을 기각하고 대립 가설을 채택(또는 유의하다고 표현)하는 결론을 내림.
P-Value가 α보다 크면, 데이터만으로는 “귀무 가설을 기각할 만한 근거가 부족하다”고 판단함.
3. 검정 통계량(Test Statistic)과 분포
예를 들어, t-검정(t-test)에서 tt-분포, 카이제곱 검정(χ2-test)에서 χ2-분포, F-검정(F-test)에서는 F-분포를 사용함.
귀무 가설이 참일 때, 해당 검정 통계량이 가지는 이론적 확률 분포(영분포 또는 귀무 분포라고도 함)를 미리 알고 있어야 함.
실제 데이터로부터 계산한 통계량이 이 분포에서 “얼마나 극단적인 위치를 차지하는가”를 통해 P-Value를 구함.
P-Value 해석의 핵심 포인트
1. P-Value는 “귀무 가설이 참일 때, 이 정도(또는 더 극단적) 관측값이 나올 확률”이지, “귀무 가설이 참일 확률” 자체가 아님.
이 부분은 굉장히 자주 혼동되는 지점임.
2. P-Value가 작다고 해서 귀무 가설이 틀렸다는 ‘절대적 증거’가 되지는 않음.
단지, 귀무 가설이 참이라면 관측된 결과가 드물게 일어난다는 것을 말해줄 뿐임.
3. P-Value는 연구 설계의 질이나 표본 수, 효과 크기 등에 따라 달라짐.
예를 들어, 표본 크기가 매우 클 경우, 실제로 효과 크기는 작지만 통계적으로 유의하게(작은 P-Value) 관측될 수 있음.
반대로 표본 크기가 작으면, 효과 크기가 큰데도 유의하지 않은 결과(P-Value가 큰 경우)가 나올 수 있음.
P-Value와 통계적 유의성, 그리고 실제적 유의성
1. 통계적 유의성(Statistical Significance)
P-Value ≤ α 일 때, 통계적으로 유의하다고 표현함.
예를 들어, α = 0.05에서 P-Value가 0.04라면, “통계적으로 유의한 차이가 있다”라고 해석함.
2. 실제적 혹은 과학적 유의성(Practical Significance)
P-Value가 작게 나왔더라도, 실제로 그 차이(효과)가 매우 미미할 수 있음.
예를 들어, 대규모 표본에서 키 차이가 0.5mm 정도인데도 통계적으로 유의할 수 있음.
그러나 이는 실제적 중요도는 거의 없는 수준일 수 있음.
3. 연구에서의 주의점
통계적 유의성과 실제적 유의성을 모두 고려해야 함.
효과 크기(effect size)와 신뢰 구간(confidence interval) 등을 함께 살펴보아야 올바른 결론을 내릴 수 있음.
P-Value의 흔한 오해와 문제점
1. “P-Value는 귀무 가설이 참일 확률을 의미한다?”
잘못된 해석임.
P-Value는 “귀무 가설이 참이라고 가정했을 때, 관측값 이상이 나올 확률”임.
2. “유의수준 α = 0.05”라는 기준이 절대적?
0.05는 관습적 편의 수준임.
실제로는 연구 분야나 맥락에 따라 α=0.01, α=0.1 등을 설정하기도 함.
“p < 0.05 => 발견!”처럼 기계적으로 사용하면 잘못된 결론을 야기할 수 있음.
3. “복수 비교 문제(Multiple Comparisons) 무시”
많은 가설(예: 수백~수천 개)을 동시에 검정하면, 우연히 유의하게 나오는 결과가 많아짐.
이 경우, 보정(Bonferroni, FDR 등)을 통해 Type I Error를 적절히 통제해야 함.
4. “P-Hacking(혹은 Data Snooping)”
실험 데이터를 수집한 후, 원하는 결과(P-Value < 0.05)가 나올 때까지 분석 방법을 바꾸거나, 표본을 늘리거나, 변수 조작 등을 하는 행위를 의미함.
이렇게 하면 P-Value가 왜곡되어 잘못된 결론을 유도하기 쉬움.
P-Value 계산 방법의 예시 : t-검정 예시
1. 가정: 두 집단 간 평균 비교 (독립 표본 t-검정).
2. 절차
2-1. 귀무 가설: “두 집단의 평균이 같다.”
2-2. 테스트 통계량 계산:

2-3. 자유도(df) 기반 t-분포에서 위 TT값(또는 양측 검정시 ∣T∣)보다 극단적인 값이 나올 확률 계산 → P-Value.
2-4. P-Value ≤ α 이면 귀무 가설 기각.
P-Value 계산 방법의 예시 : 카이제곱 검정 예시
1. 가정: 범주형 자료에서 기대 빈도와 관측 빈도가 얼마나 다른지 확인(적합도 검정, 독립성 검정 등).
2. 절차
2-1. 귀무 가설: “범주 간 차이(또는 관계)가 없다.”
2-2. 테스트 통계량:
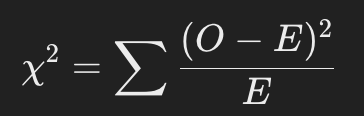
(여기서 OO는 관측 빈도, EE는 기대 빈도)
2-3. 카이제곱 분포(χ2 분포)를 사용해 해당 통계량 이상의 값이 나올 확률 → P-Value.
2-4. P-Value ≤ α 이면 귀무 가설 기각.
베이즈적 관점과의 비교
P-Value는 빈도주의 관점에서 정의되므로, 귀무 가설이 참이라는 전제하에서만 확률을 정의함.
베이즈 통계학에서는 사전 확률(prior), 사후 확률(posterior) 개념을 사용하여 “가설이 참일 확률” 자체를 모델링할 수 있음.
베이즈 접근에서는 ‘Bayes Factor’나 ‘Posterior Probability’ 같은 개념을 사용해 가설에 대한 직접적인 확률적 해석을 시도함.
실무에서의 주의사항 및 권장 방법
1. 효과 크기(Effect Size)와 신뢰 구간(Confidence Interval)을 함께 제시
P-Value만 제시해서는 실제 효과의 의미를 제대로 알기 어려움.
신뢰 구간을 보면 추정의 정밀도를 파악할 수 있음.
2. 연구 설계 단계에서의 표본 크기 설정(Power Analysis)
사전에 충분한 표본 크기를 계산(Statistical Power 계산)해 두어야, 유의미한 효과를 검출할 수 있음.
3. 여러 가설을 동시에 검정하는 경우 보정
FDR(위양성 발견율) 제어, Bonferroni correction 등으로 다중 검정 문제를 조정해야 함.
4. 재현 가능성(Replication Crisis)에 대한 인식
한 번의 실험에서 유의미한 P-Value를 얻었더라도, 동일 연구를 재현했을 때 같은 결과가 나와야 신뢰할 만함.
5. 연구 전 등록(Pre-registration)
미리 연구 설계를 정하고, 분석 방법과 가설 등을 공표함으로써 ‘P-Hacking’을 방지하는 방법이 점차 권장되고 있음.
정리
P-Value는 귀무 가설이 참이라는 전제하에서, 관찰된(또는 그보다 더 극단적인) 통계량이 나올 확률을 의미함.
값이 작을수록 “귀무 가설과 맞지 않는 결과”임을 의미하지만, 이것이 곧 “귀무 가설이 거짓임을 100% 증명”하는 것은 아님.
통계적 유의성은 실제적 혹은 과학적 유의성과 다를 수 있으며, 여러 가설 검정에서 발생하는 오류와 잘못된 해석을 예방하기 위해 주의 깊은 연구 설계와 결과 해석이 필요함.
P-Value는 이분법적 기준(p < 0.05)보다, 효과 크기, 신뢰 구간, 복수 비교 보정 등의 다른 통계적 지표와 함께 해석하는 것이 바람직함.
결론
P-Value는 가설 검정에서 귀무 가설 하에 데이터가 관측될 “드문 정도”를 나타내는 필수 지표임.
하지만 P-Value 자체가 가설의 진위 여부를 직접적으로 알려주지 않는다는 점과, 연구자들의 잘못된 사용 또는 해석으로 인해 왜곡된 결론이 나올 수 있다는 점은 반드시 인지해야 함.
따라서 전문가 수준에서는 P-Value를 다른 통계 지표와 함께 균형 있게 해석하고, 적절한 표본 크기 결정과 다중 검정 보정, 연구 전 등록 등을 통해 신뢰도와 재현 가능성을 높이는 방법을 적극 고려해야 함.
'Database > SQL' 카테고리의 다른 글
| [SQL] 버퍼 캐시 (0) | 2025.01.20 |
|---|---|
| [SQL] DML 실행시 데이터베이스 프로세스 (0) | 2025.01.20 |
| [MySQL] Auto Increment, 컬럼 생성 옵션 종류 (0) | 2024.06.15 |
| [MySQL] 외래키, 복합키 (1) | 2024.06.15 |
| [MySQL] 인덱스, 기본키 (1) | 2024.06.15 |