
이번 테스트에서 작성중인 깃허브는 다음과 같다.
https://github.com/ParkGyeongTae/spark-pgt/tree/main/1_spark-cluster
GitHub - ParkGyeongTae/spark-pgt
Contribute to ParkGyeongTae/spark-pgt development by creating an account on GitHub.
github.com
다른 블로그들을 보면 spark-shell 또는 pyspark 또는 spark-submit 명령어를 사용시 --num-executors 옵션을 주면 익스큐터의 갯수를 설정할 수 있다고들 한다.
하지만 나는 이 방식이 적용되지 않았다.... 이유는 잘 모르겠으나, 해결방법은 찾은 것 같다.
왜 다른 블로그에서는 다들 된다고 하는지 한번 더 확인해봐야겠다..
현재 내 스파크 버전은 다음과 같다.
spark-3.2.1-bin-hadoop3.2
클러스터 구조는 스탠드얼론 형식으로 돼 있고,
마스터1개, 워커3개로 구성돼있다.
마스터 웹 ui 로 들어가면 다음과 같이 확인할 수 있다.

먼저 아무런 옵션 없이 spark-shell 을 실행시키고 종료시켜보자.
./spark/bin/spark-shell --master spark://spark-master:17077 --name spark-shell-pgt

가장 최근에 실행된 어플리케이션을 클릭해보자

아무런 조건 없이 실행시켰더니 결과는 다음과 같았다.
3개의 익스큐터, 익스큐터당 4개의 코어, 익스큐터당 1기가의 메모리를 사용하는 것을 확인할 수 있다.
이번에는 이 설정에 맞춰서 옵션과 함께 spark-shell 을 실행시키고 종료시켜보자!
./spark/bin/spark-shell --master spark://spark-master:17077 --name spark-shell-pgt --executor-cores 4 --executor-memory 1g

해당 어플리케이션을 확인해보자
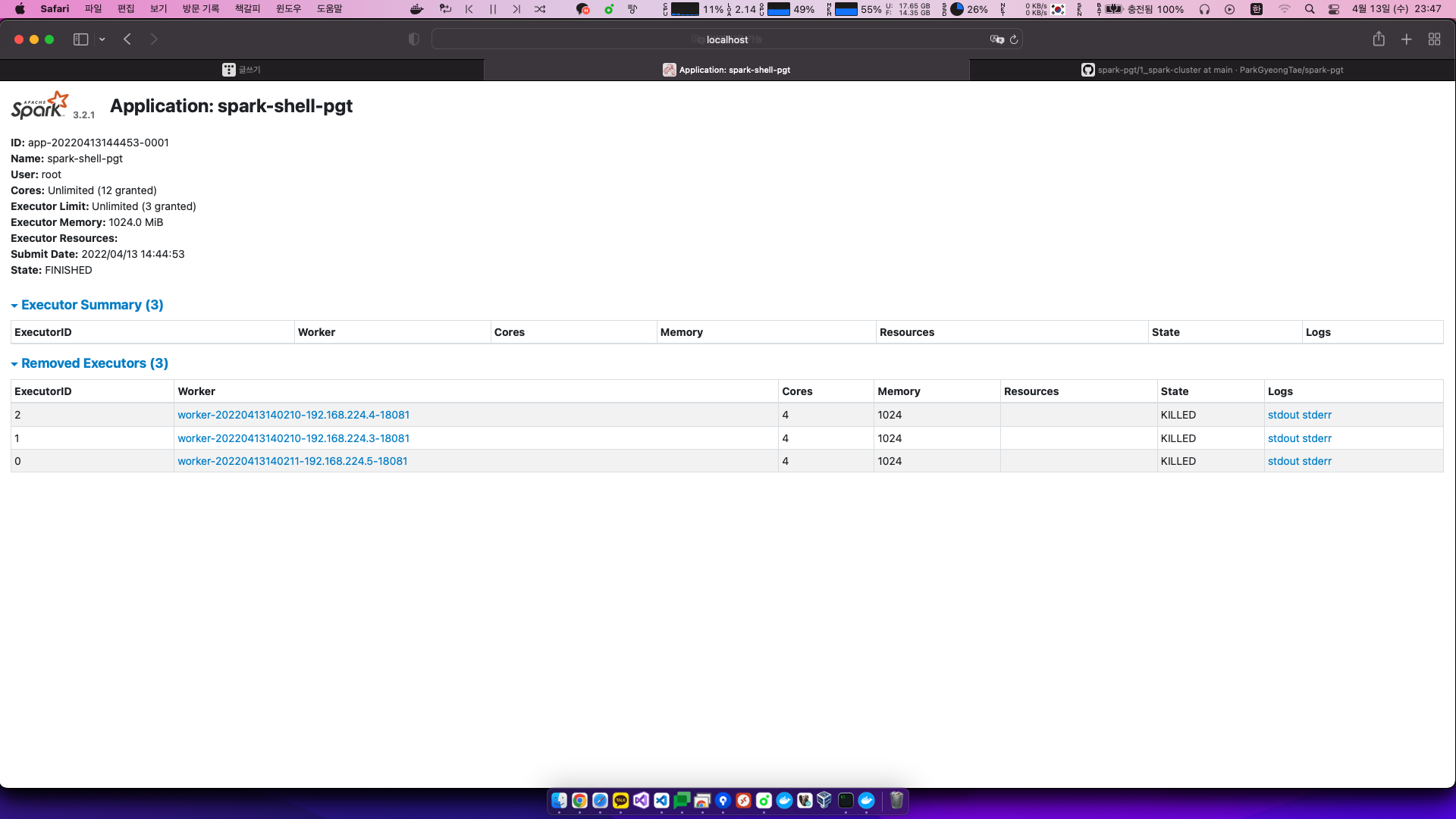
원하는대로 디폴트설정과 같은 성능의 애플리케이션이 실행됐다.
3개의 익스큐터였고 익스큐터당 4개의 코어를 사용했으며 메모리는 1기가씩 적용됐다.
내가 원한건 익스큐터의 갯수를 조정하고싶었는데,
블로그를 참고하니 --num-executors 이 옵션을 이용한다고한다.
스파크의 버전이 올라가면서 명령어가 바뀐건지.. 아니면 내가 이해를 못한건지는 확인해봐야겠다.
먼저 --num-executors 이것을 적용해서 해보자
--num-executors 옵션에 2를 넣어서 2개의 익스큐터만 실행하도록 해보자
그러면 예상되는 결과는 4개의 코어를 갖고 1기가의 메모리를 가진 2개의 익스큐터가 실행되기를 바란다.
./spark/bin/spark-shell --master spark://spark-master:17077 --name spark-shell-pgt --executor-cores 4 --executor-memory 1g --num-executors 2

애플리케이션은 잘 실행되고 종료됐으나,
결과는 다음과 같다.

spark-shell, pyspark, spark-submit 모두 해봤으나 결과는 동일했고,
내 예상은 --num-executors 이 옵션이 맞지 않는 것 같다.
그래서 찾은 옵션은 --total-executor-cores 옵션이다!
익스큐터가 사용할 코어의 전체 갯수를 지정해주자.
--executor-cores 4 --executor-memory 1g --total-executor-cores 8
익스큐터당 4개의 코어를 갖고 1기가의 메모리를 갖지만 전체 익스큐터의 코어수는 8이다.
./spark/bin/spark-shell --master spark://spark-master:17077 --name spark-shell-pgt --executor-cores 4 --executor-memory 1g --total-executor-cores 8

결과를 확인해보자.

내가 원하는 방식으로 적용됐다!
애플리케이션을 제출할 때 전체 익스큐터의 갯수를 조정하고싶으면
--num-executors 이 아닌 --total-executor-cores 이걸 사용해보자!
p.s 블로그를 쓰면서 알게됐는데,
--num-executors 이거는 스파크의 마스터로 yarn 을 사용할 때에만 쓸 수 있는 것 같다...
spark-shell --help 의 내용이 다음과 같다.

root@spark-master:/home# spark-shell --help
Usage: ./bin/spark-shell [options]
Scala REPL options:
-I <file> preload <file>, enforcing line-by-line interpretation
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn,
k8s://https://host:port, or local (Default: local[*]).
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor. File paths of these files
in executors can be accessed via SparkFiles.get(fileName).
--archives ARCHIVES Comma-separated list of archives to be extracted into the
working directory of each executor.
--conf, -c PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Cluster deploy mode only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
Spark standalone, Mesos or K8s with cluster deploy mode only:
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone, Mesos and Kubernetes only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone, YARN and Kubernetes only:
--executor-cores NUM Number of cores used by each executor. (Default: 1 in
YARN and K8S modes, or all available cores on the worker
in standalone mode).
Spark on YARN and Kubernetes only:
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--principal PRINCIPAL Principal to be used to login to KDC.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above.
Spark on YARN only:
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
.. 어리석었다.
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] Apache Spark + Apache Zeppelin 실행하기 (0) | 2022.04.15 |
|---|---|
| [Spark] Stand-Alone 실행 중 Master 컨테이너 중지 후 실행 (0) | 2022.04.15 |
| [Spark] Spark Cluster 간단하게 만들어보기 (standalone) (0) | 2022.04.13 |
| [Spark] org.apache.spark.deploy.master.Master running as process 580. Stop it first. (0) | 2022.04.13 |
| [Spark] 스파크 마스터 최초 실행시 얻을 수 있는 로그 내용 (0) | 2022.04.13 |