
데이터 프레임 기본 만들기
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']])
print(df)
첫번째 행만 출력해보기
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']])
print(df.head(1))
마지막 행만 출력해보기
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']])
print(df.tail(1))
데이터프레임 만들 때 열의 이름을 지정해보기
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'])
print(df)
데이터프레임을 만들 때 인덱스 이름을 a, b, c 로 해보기
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
print(df)
데이터프레임의 컬럼 이름을 변경해보기
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df.columns = ['idd', 'krr', 'enn']
print(df)
데이터프레임 인덱스를 나중에 변경해보기
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df.index = ['aa', 'bb', 'cc']
print(df)
각 컬럼의 타입 확인하기
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
print(df.info())
모든 행을 문자열 형으로 변환해보자
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'string', 'kr':'string', 'en':'string'})
print(df.info())
id 컬럼만 정수형으로 변경해보자
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int', 'kr':'string', 'en':'string'})
print(df.info())
id 컬럼을 int 32, int 16 타입으로 변경해보자
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int32', 'kr':'string', 'en':'string'})
print(df.info())
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int16', 'kr':'string', 'en':'string'})
print(df.info())
int8, int4로 수정해보자
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int8', 'kr':'string', 'en':'string'})
print(df.info())
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int4', 'kr':'string', 'en':'string'})
print(df.info())
int4라는 타입은 없는것을 확인할 수 있다.
다시 int형으로 수정해보자
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int', 'kr':'string', 'en':'string'})
print(df.info())
모든 데이터*2를 해보자
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int', 'kr':'string', 'en':'string'})
df = df*2
print(df)
데이터프레임을 하나 더 만들어보자
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int', 'kr':'string', 'en':'string'})
df_sub = pd.DataFrame([['4', '황', 'hwang'],
['5', '이', 'lee'],
['6', '정', 'jeong']],
columns = ['id', 'kr', 'en'],
index = ['d', 'e', 'f'])
print(df)
print(df_sub)
두 데이터프레임을 위아래로 붙여보자
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int', 'kr':'string', 'en':'string'})
df_sub = pd.DataFrame([['4', '황', 'hwang'],
['5', '이', 'lee'],
['6', '정', 'jeong']],
columns = ['id', 'kr', 'en'],
index = ['d', 'e', 'f'])
df_result = pd.concat([df, df_sub])
print(df_result)
이번에는 df라는 데이터프레임만 2개를 위아래로 붙여보자
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int', 'kr':'string', 'en':'string'})
df_sub = pd.DataFrame([['4', '황', 'hwang'],
['5', '이', 'lee'],
['6', '정', 'jeong']],
columns = ['id', 'kr', 'en'],
index = ['d', 'e', 'f'])
df_result = pd.concat([df, df])
print(df_result)
데이터프레임 두개 병합할 때 인덱스 무시하기
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int', 'kr':'string', 'en':'string'})
df_sub = pd.DataFrame([['4', '황', 'hwang'],
['5', '이', 'lee'],
['6', '정', 'jeong']],
columns = ['id', 'kr', 'en'],
index = ['d', 'e', 'f'])
df_result = pd.concat([df, df_sub], ignore_index=True)
print(df_result)
데이터프레임 좌우로 붙이기
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int', 'kr':'string', 'en':'string'})
df_sub = pd.DataFrame([['4', '황', 'hwang'],
['5', '이', 'lee'],
['6', '정', 'jeong']],
columns = ['id', 'kr', 'en'],
index = ['d', 'e', 'f'])
df_result = pd.concat([df, df_sub], axis=1)
print(df_result)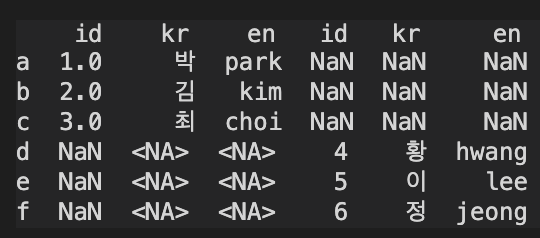
컬럼이름 변경하기
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int', 'kr':'string', 'en':'string'})
df_sub = pd.DataFrame([['4', '황', 'hwang'],
['5', '이', 'lee'],
['6', '정', 'jeong']],
columns = ['id', 'kr', 'en'],
index = ['d', 'e', 'f'])
df_result = pd.concat([df, df_sub], axis=1)
df_result.columns = ['id_df', 'kr_df', 'en_df', 'id_dfsub', 'kr_dfsub', 'en_dfsub']
print(df_result)
합친 상태의 데이터 타입 확인하기
import pandas as pd
df = pd.DataFrame([['1', '박', 'park'],
['2', '김', 'kim'],
['3', '최', 'choi']],
columns = ['id', 'kr', 'en'],
index = ['a', 'b', 'c'])
df = df.astype({'id':'int', 'kr':'string', 'en':'string'})
df_sub = pd.DataFrame([['4', '황', 'hwang'],
['5', '이', 'lee'],
['6', '정', 'jeong']],
columns = ['id', 'kr', 'en'],
index = ['d', 'e', 'f'])
df_result = pd.concat([df, df_sub], axis=1)
df_result.columns = ['id_df', 'kr_df', 'en_df', 'id_dfsub', 'kr_dfsub', 'en_dfsub']
print(df_result.info())
'Programming Language > Python' 카테고리의 다른 글
| [Conda] Error -> Could not find conda environment: (0) | 2022.04.14 |
|---|---|
| [python] 데이터프레임 자유롭게 병합해보기 (0) | 2022.02.26 |
| [python] invalid literal for int() with base 10: '박' 타입변환 불가능 (0) | 2022.02.26 |
| [python] data type 'int4' not understood int4타입 없음 (0) | 2022.02.26 |
| [python] 'Only a column name can be used for the key in a dtype mappings argument.' 컬럼 타입 변경 (0) | 2022.02.26 |