
기본형
df = pd.read_csv('/kaggle/input/london-bike-sharing-dataset/london_merged.csv')
df.head()
데이터의 구조, 타입, 컬럼 확인하기
print('< 데이터 구조 >\n', df.shape)
print('< 데이터 타입 >\n', df.dtypes)
print('< 데이터 컬럼 >\n', df.columns)
timestamp가 object 형인 것을 확인할 수 있다.
다음은 parse_dates 를 사용해보자.
df = pd.read_csv('/kaggle/input/london-bike-sharing-dataset/london_merged.csv', parse_dates = ['timestamp'])
# df = pd.read_csv('/kaggle/input/london-bike-sharing-dataset/london_merged.csv')
df.head()
print('< 데이터 구조 >\n', df.shape)
print('< 데이터 타입 >\n', df.dtypes)
print('< 데이터 컬럼 >\n', df.columns)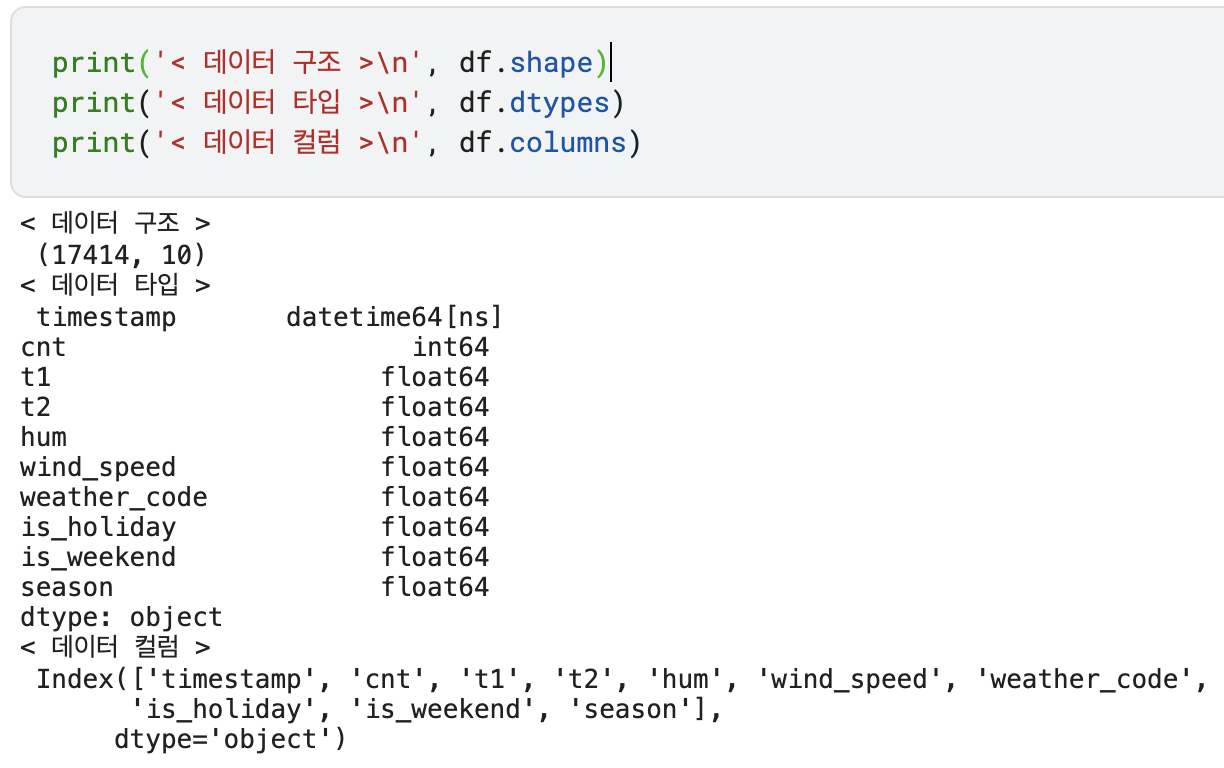
timestamp의 데이터타입이 datetime64[ns] 로 변한 것을 확인할 수 있다.
'Programming Language > Python' 카테고리의 다른 글
| [Kaggle] London Bike Sharing Dataset 데이터 전처리 해보기 (0) | 2022.05.08 |
|---|---|
| [Python] 데이터프레임의 구조, 타입, 컬럼 확인하는 방법 (0) | 2022.05.04 |
| [Kaggle] London bike sharing dataset 그래프 그려보기 (0) | 2022.05.04 |
| [Kaggle] London bike sharing dataset 데이터 살펴보기 (0) | 2022.05.04 |
| [Python] RL, 강화학습 Frozen-Lake Dummy Q-Learning 실행하는 방법 (0) | 2022.05.02 |