
https://www.kaggle.com/datasets/hmavrodiev/london-bike-sharing-dataset
London bike sharing dataset
Historical data for bike sharing in London 'Powered by TfL Open Data'
www.kaggle.com
import numpy as np
import pandas as pd
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
df = pd.read_csv('/kaggle/input/london-bike-sharing-dataset/london_merged.csv', parse_dates = ['timestamp'])
# df = pd.read_csv('/kaggle/input/london-bike-sharing-dataset/london_merged.csv')
df.head()
print('< 데이터 구조 >\n', df.shape)
print('< 데이터 타입 >\n', df.dtypes)
print('< 데이터 컬럼 >\n', df.columns)
print('< 결측치 >')
df.isna().sum()
print('< 결측치 시각화 >')
msno.matrix(df)
plt.show()
df['year'] = df['timestamp'].dt.year
df['month'] = df['timestamp'].dt.month
df['dayofweek'] = df['timestamp'].dt.dayofweek
df['hour'] = df['timestamp'].dt.hour
df.head()
df['year'].value_counts()
# df['month'].value_counts()
# df['dayofweek'].value_counts()
# df['weather_code'].value_counts()
a, b = plt.subplots(1, 1, figsize=(10, 5))
sns.boxplot(df['year'], df['cnt'])
a, b = plt.subplots(1,1, figsize=(10, 5))
sns.boxplot(df['month'], df['cnt'])
a, b = plt.subplots(1,1, figsize=(10, 5))
sns.boxplot(df['dayofweek'], df['cnt'])
a, b = plt.subplots(1,1, figsize=(10, 5))
sns.boxplot(df['hour'], df['cnt'])
def plot_bar(data, feature):
fig = plt.figure(figsize = (12, 3))
sns.barplot(x = feature, y = 'cnt', data = data, palette = 'Set3')
plot_bar(df, 'hour')
plot_bar(df, 'dayofweek')
def is_outliers(s):
lower_limit = s.mean() - (s.std() * 3)
upper_limit = s.mean() + (s.std() * 3)
return ~s.between(lower_limit, upper_limit)
df_out = df[~df.groupby('hour')['cnt'].apply(is_outliers)]
print('이상치 제거 전 :', df.shape)
print('이상치 제거 후 :', df_out.shape)
df_out.dtypes
df_out['weather_code'] = df_out['weather_code'].astype('category')
df_out['season'] = df_out['season'].astype('category')
df_out['year'] = df_out['year'].astype('category')
df_out['month'] = df_out['month'].astype('category')
df_out['hour'] = df_out['hour'].astype('category')
df_out.dtypes
df_out['season']
df_out = pd.get_dummies(df_out, columns=['weather_code', 'season', 'year', 'month', 'hour'])
df_out.head()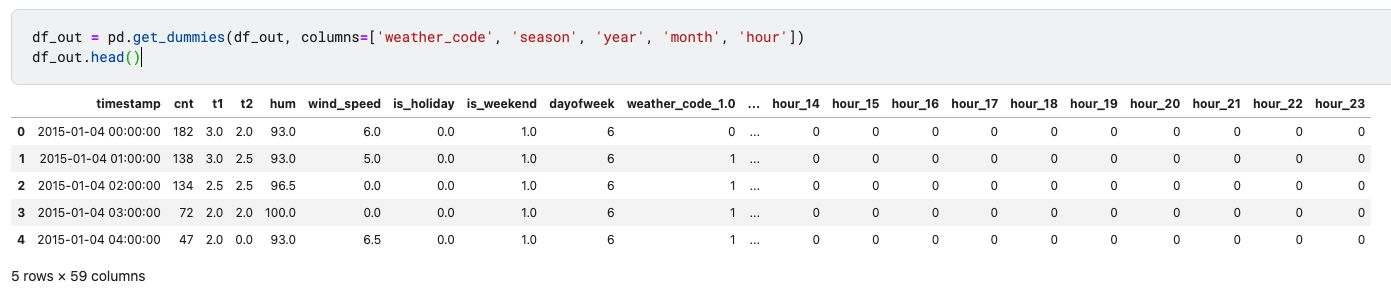
df_out.shape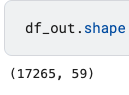
df_y = df_out['cnt']
df_x = df_out.drop(['timestamp', 'cnt'], axis = 1)
df_x.head()
df_y.head()
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(df_x, df_y, random_state = 1004, test_size = 0.3, shuffle = False)
print('x_train의 구조 :', x_train.shape)
print('y_train의 구조 :', y_train.shape)
print('x_test의 구조 :', x_test.shape)
print('y_test의 구조 :', y_test.shape)
'Programming Language > Python' 카테고리의 다른 글
| [Kaggle] 런던자전거 - 머신러닝, 딥러닝 모델 비교해보기 (0) | 2022.05.11 |
|---|---|
| [Kaggle] London Bike Sharing Dataset 딥러닝 모델 만들어보기 (0) | 2022.05.08 |
| [Python] 데이터프레임의 구조, 타입, 컬럼 확인하는 방법 (0) | 2022.05.04 |
| [Python] read_csv의 parse_dates 옵션 사용해보기 (0) | 2022.05.04 |
| [Kaggle] London bike sharing dataset 그래프 그려보기 (0) | 2022.05.04 |