
import pandas as pd
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.master('local') \
.appName('my_pyspark_app') \
.getOrCreate()
df_pandas = pd.DataFrame({
'id': [0, 1, 2, 3, 4],
'name': ['kim', 'kim', 'park', 'park', 'lee'],
'score': [100, 90, 80, 70, 60]
})
df_spark = spark.createDataFrame(df_pandas)
print(df_pandas)
df_spark.show()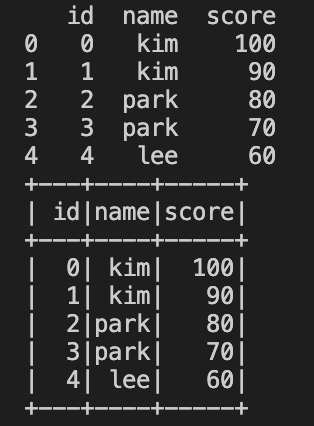
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] List로 pyspark dataframe 만드는 방법 (0) | 2023.01.14 |
|---|---|
| [Spark] Row 함수를 이용해서 Pyspark dataframe 만드는 방법 (0) | 2023.01.14 |
| [Spark] Pyspark dataframe 안의 List 처리하는 방법 (0) | 2022.12.16 |
| [Spark] TypeError: Can not infer schema for type: <class 'str'> 해결 방법 (0) | 2022.12.16 |
| [Spark] Pyspark json List를 처리하는 방법 (0) | 2022.12.16 |