
jdk 버전 : jdk-8u321-linux-x64
스파크 버전 : spark-3.2.1-bin-hadoop3.2
스파크 클러스터 실행 상태 확인
jps
ps -eo user,pid,ppid,rss,size,vsize,pmem,pcpu,time,cmd --sort -rss | head -n 100
spark web ui

이제 제플린 노트북을 실행시켜보자
그리고 간단한 실행을해보자
sc
sc.parallelized(1 to 100).count
애플리케이션이 실행 됐는지 스파크 웹 ui를 확인
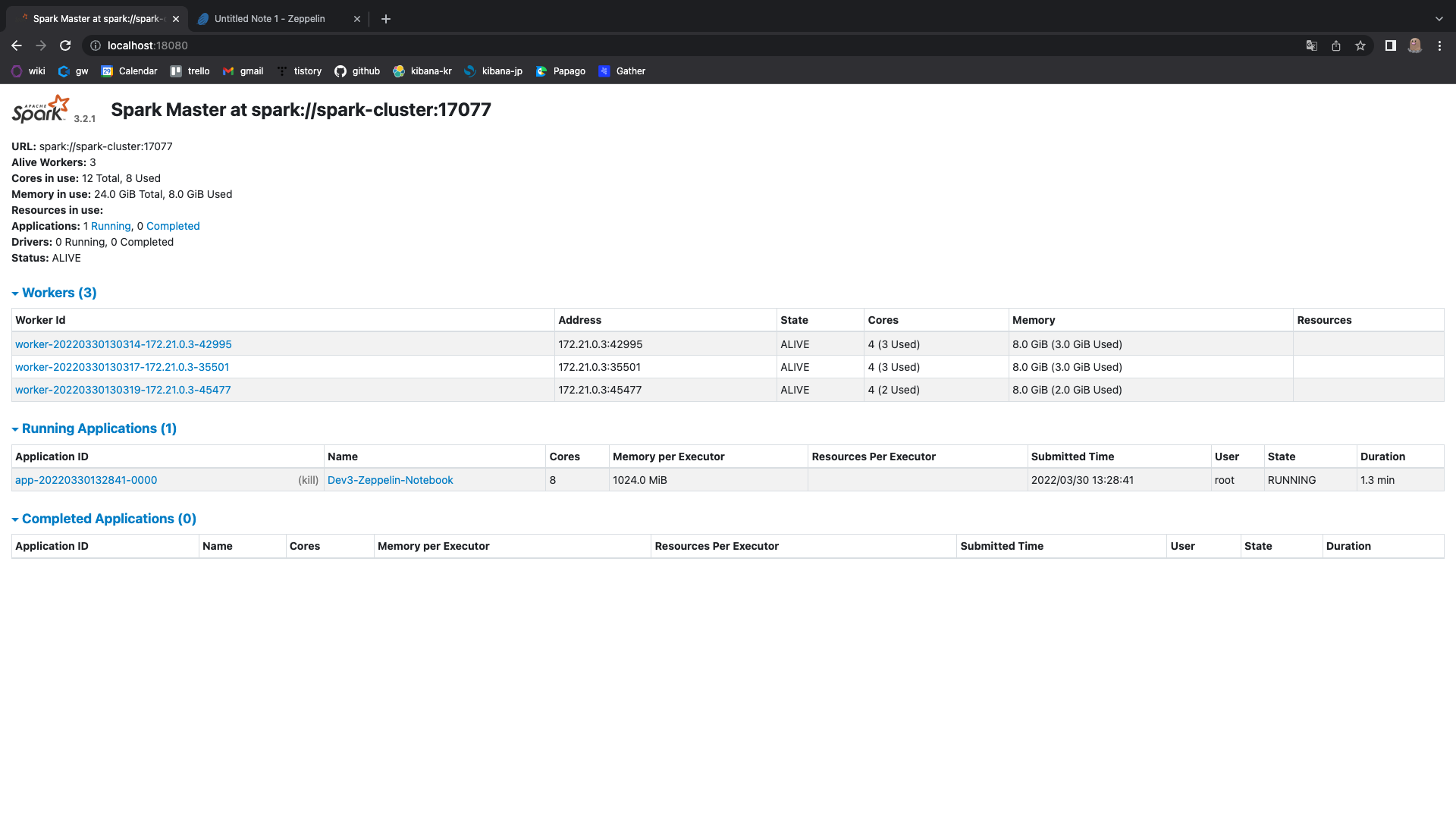
실행이 잘 됐고,
익스큐터가 어떻게 구성됐는지 확인해보자

제플린을 사용하는 애플리케이션을
총 8코어, 8기가를 사용하는데
익스큐터도 8개를 사용해서
익스큐터당 1코어, 1기가씩 사용하는 것으로 확인된다.
이제 애플리케이션을 실행했으니 코어, 메모리는 어떤지 확인해보자
jps
ps -eo user,pid,ppid,rss,size,vsize,pmem,pcpu,time,cmd --sort -rss | head -n 100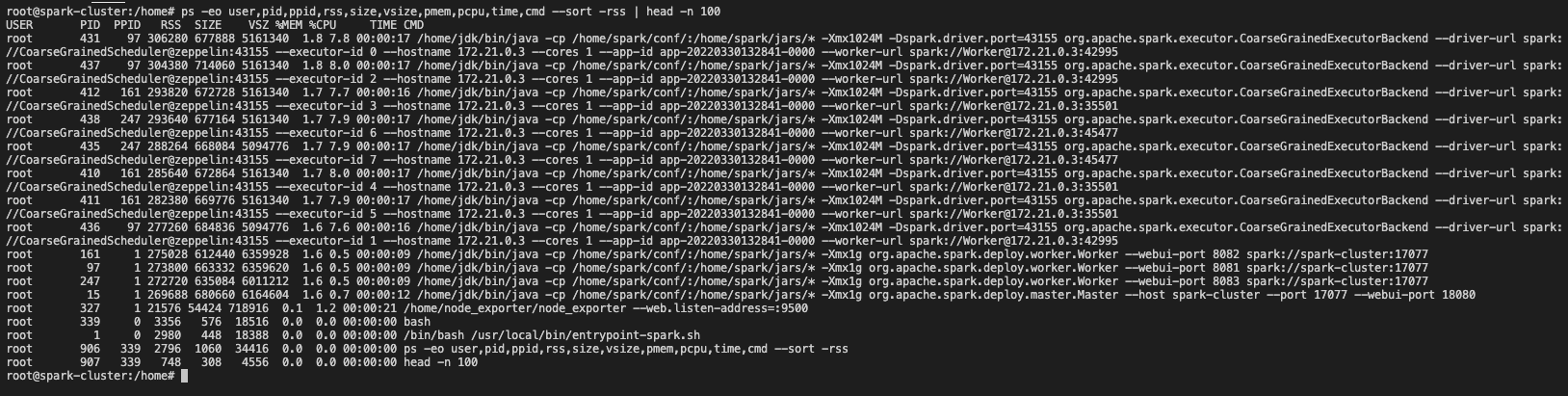
cpu와 메모리를 더 사용하는 것을 확인할 수있다.
이번에는 제플린노트북에서 애플리케이션을 사용 중지 해보자
sc.stop
스파크 웹 ui

jps
코어마다 갖고 있던 jps가 없어졌다.
cpu, memory 를 확인해보자
ps -eo user,pid,ppid,rss,size,vsize,pmem,pcpu,time,cmd --sort -rss | head -n 100
애플리케이션 제출 전으로 cpu와 memory가 돌아온 것을 확인할 수 있다.
'Data Engineering > Spark' 카테고리의 다른 글
| [spark] bash: javac: command not found (0) | 2022.04.10 |
|---|---|
| [spark] 스파크 설치 전 jdk 설치하기 (0) | 2022.04.10 |
| [Spark] Apache Spark Stand-Alone CPU, 메모리 사용률 확인하기 (0) | 2022.03.30 |
| [Spark] Apache Spark Stand-Alone 실행, 종료하는 방법 (0) | 2022.03.30 |
| [Spark] 스파크 메인 웹 UI (스파크 마스터) 포트 변경하는 방법 (0) | 2022.03.30 |