
컨테이너 1 : NameNode, NodeManager, ResourceManager, JobHistoryServer + MasterNode(Spark)
컨테이너 2 : SecondaryNameNode, WorkerNode + WorkerNode(Spark)
컨테이너 3 : WorkerNode + WorkerNode(Spark)
컨테이너 4 : WorkerNode + WorkerNode(Spark)
컨테이너 5 : WorkerNode + WorkerNode(Spark)
컨테이너 1 : NameNode, NodeManager, ResourceManager, HistoryManager + MasterNode(Spark)

1264 HistoryServer
1152 Master
737 ResourceManager
261 NameNode
1110 JobHistoryServer
1366 Jps
컨테이너 2 : SecondaryNameNode, WorkerNode + WorkerNode(Spark)

288 NodeManager
416 Worker
82 DataNode
551 Jps
188 SecondaryNameNode
컨테이너 3 : WorkerNode + WorkerNode(Spark)

83 DataNode
411 Jps
331 Worker
203 NodeManager
컨테이너 4 : WorkerNode + WorkerNode(Spark)

83 DataNode
411 Jps
331 Worker
203 NodeManager
컨테이너 5 : WorkerNode + WorkerNode(Spark)
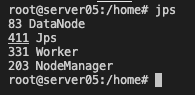
83 DataNode
411 Jps
331 Worker
203 NodeManager
하둡 클러스터(얀)과 스파크 클러스터만 실행시켰을 때 도커의 메모리 사용을 한번 보자

localhost:9870을 들어가보자





localhost:8088에 들어가보자


'Data Engineering > Spark' 카테고리의 다른 글
| [Zookeeper] 주키퍼 설정파일 zoo.cfg 정리 (0) | 2022.03.25 |
|---|---|
| [Spark] Spark on Yarn Cluster 어플리케이션 실행 전후 각 서버별 jps 상태 확인하기 (0) | 2022.03.20 |
| [Spark] 로컬에서 제플린 테스트시 사용하는 dockerfile (0) | 2022.03.20 |
| [Spark] 로컬에서 스파크 클러스터 테스트시 사용하는 dockerfile (0) | 2022.03.20 |
| [Spark] 제플린에서 spark context 옵션에 대해 살펴보기 (0) | 2022.03.19 |