
https://github.com/ParkGyeongTae/spark-pgt/tree/main/2_spark-cluster-zeppelin
GitHub - ParkGyeongTae/spark-pgt
Contribute to ParkGyeongTae/spark-pgt development by creating an account on GitHub.
github.com
입력
%spark
val data = sc.parallelize(1 to 100)
data.count출력
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[3] at parallelize at <console>:26
res13: Long = 100
입력
%spark
val data = sc.parallelize(1 to 100)
data.take(10)출력
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[4] at parallelize at <console>:26
res14: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
입력
%spark
val data = sc.parallelize(1 to 100 by 5)
data.take(10)출력
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[5] at parallelize at <console>:26
res15: Array[Int] = Array(1, 6, 11, 16, 21, 26, 31, 36, 41, 46)
입력
%spark
val data = sc.parallelize(0 to 100 by 5)
data.take(10)출력
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at parallelize at <console>:26
res16: Array[Int] = Array(0, 5, 10, 15, 20, 25, 30, 35, 40, 45)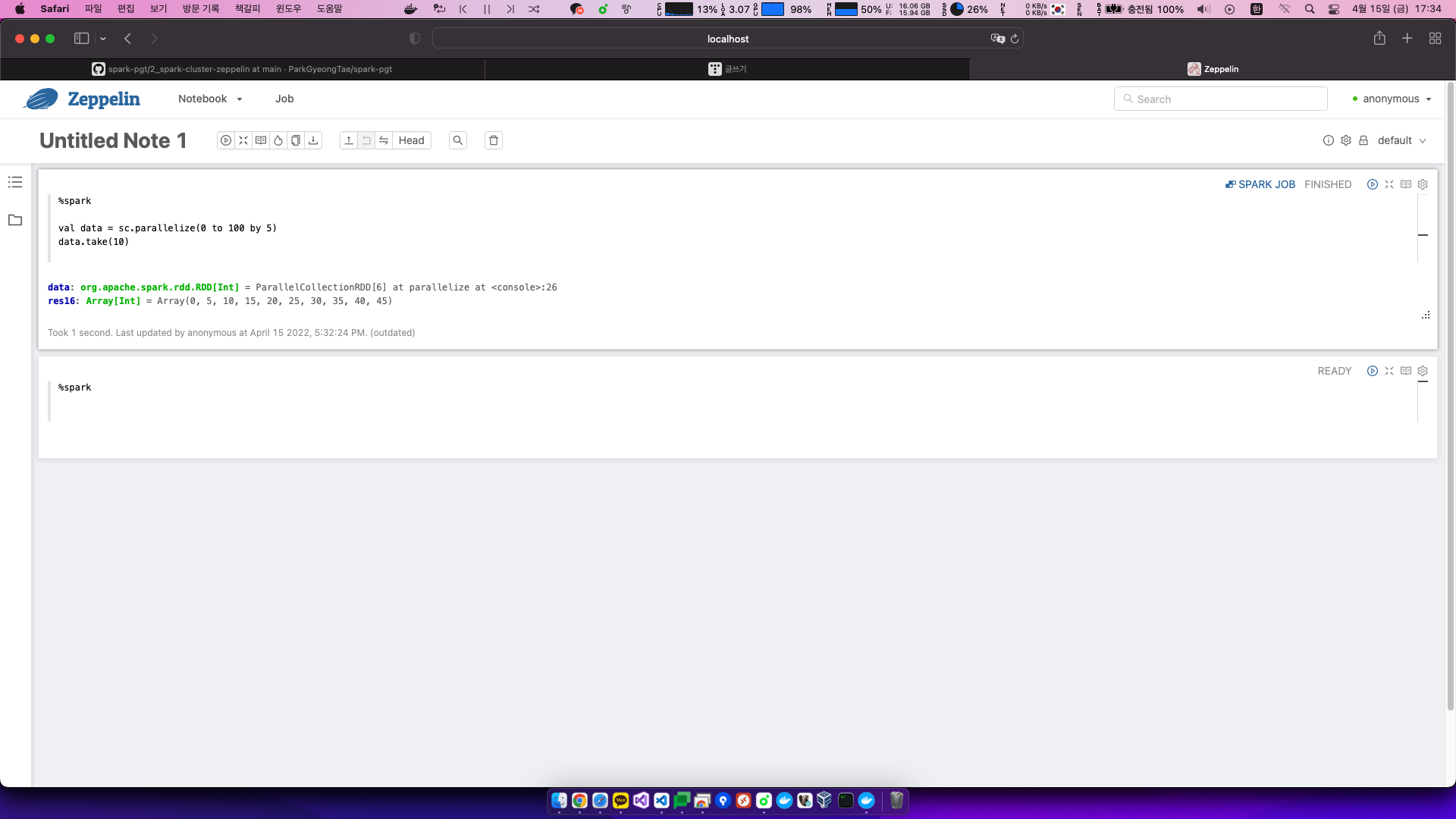
입력
%spark
val data = sc.parallelize(0 to 100 by 5)
data.collect출력
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[7] at parallelize at <console>:26
res17: Array[Int] = Array(0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100)
입력
%spark
val data = sc.parallelize(0 to 10 by 1)
data.take(5)출력
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[8] at parallelize at <console>:26
res18: Array[Int] = Array(0, 1, 2, 3, 4)
입력
%spark
val data = sc.parallelize(1 to 10 by 1)
data.take(100)출력
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at parallelize at <console>:26
res21: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
입력
%spark
val data = sc.parallelize(1 to 10 by 1)
data.reduce((a, b) => a + b)출력
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at parallelize at <console>:26
res22: Int = 55
입력
%spark
val data = sc.parallelize(1 to 10 by 1)
data.reduce((a, b) => a * b)출력
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[13] at parallelize at <console>:26
res23: Int = 3628800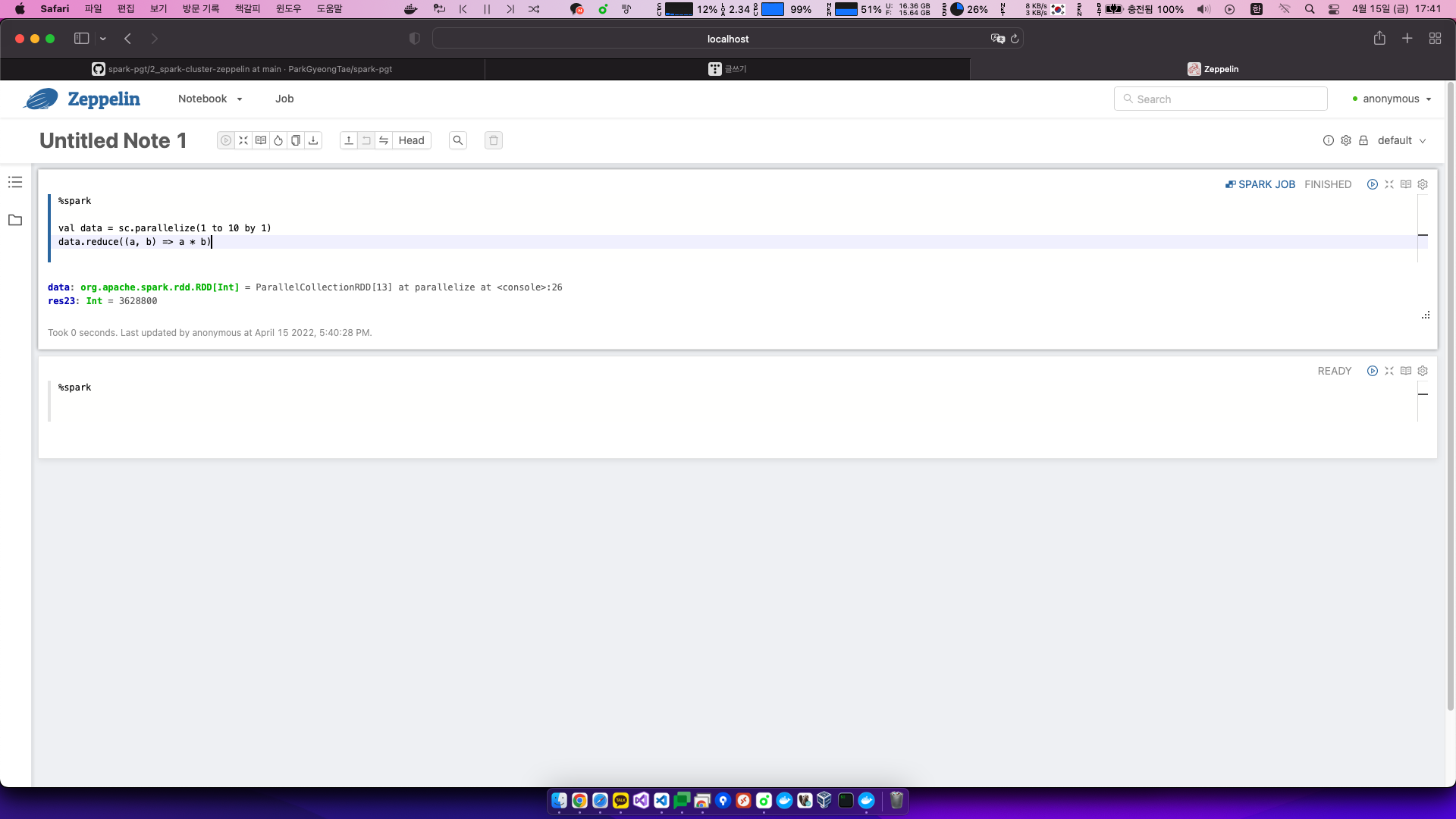
입력
%spark
val data = sc.parallelize(1 to 10 by 1)
data.map(x => if(x <= 5) x else 0).reduce((x, y) => x + y)출력
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[14] at parallelize at <console>:26
res24: Int = 15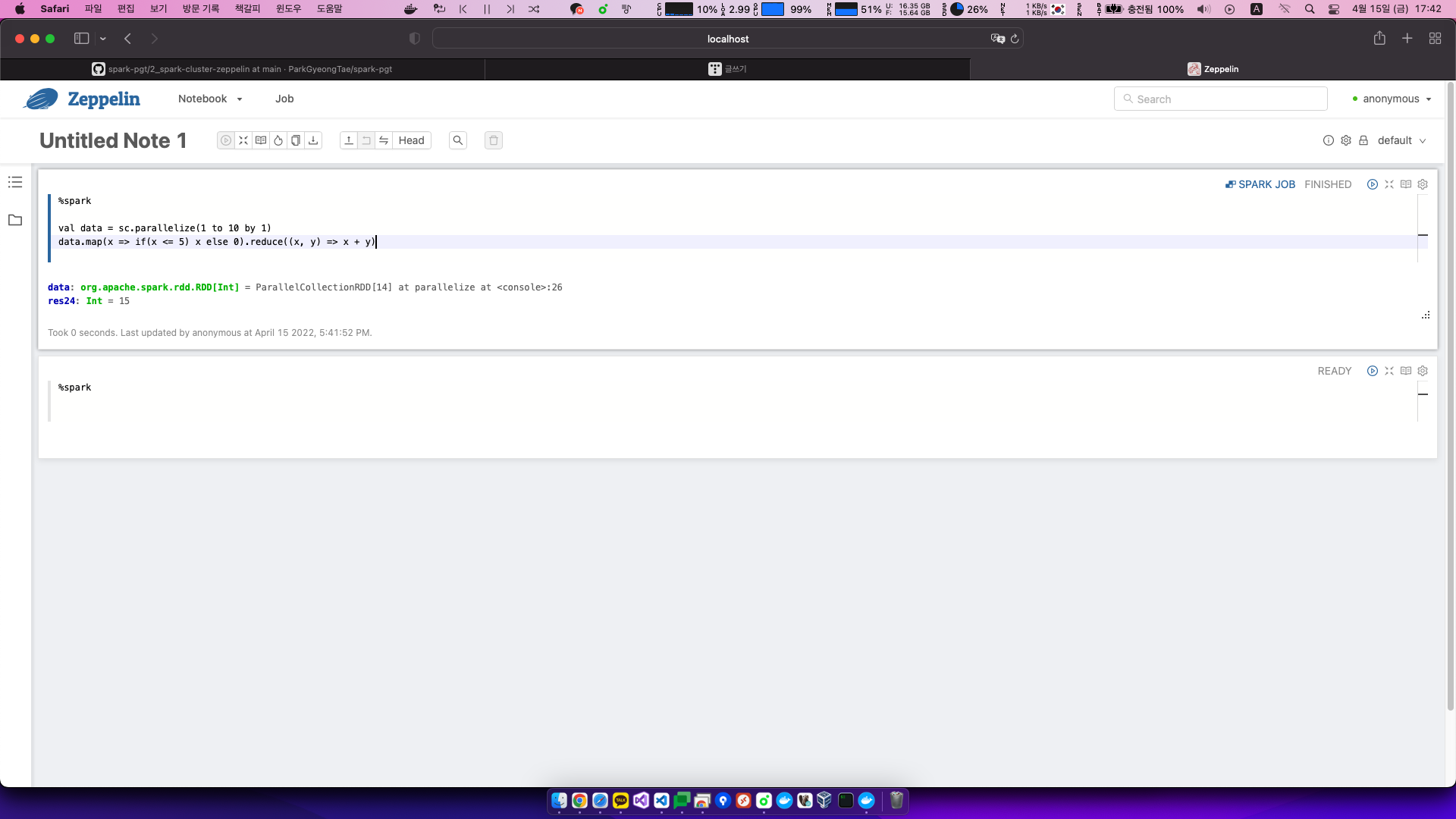
입력
%spark
val data = sc.parallelize(1 to 10 by 1)
data.filter(_ >= 5).reduce(_ + _)출력
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[16] at parallelize at <console>:26
res25: Int = 45
입력
%spark
val data = sc.parallelize(1 to 10 by 1)
data.filter(_ <= 6).reduce(_ + _)출력
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[18] at parallelize at <console>:26
res26: Int = 21
입력
%spark
val data = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val dataRdd = sc.parallelize(data)
dataRdd.reduce(_ + _)출력
data: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
dataRdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[21] at parallelize at <console>:28
res28: Int = 55
입력
%spark
val data = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val dataRdd = sc.parallelize(data)
dataRdd.reduce((x, y) => x + y)출력
data: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
dataRdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[22] at parallelize at <console>:28
res29: Int = 55
입력
%spark
val data = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val dataRdd = sc.parallelize(data)
val sum = dataRdd.map(x => (1, x)).reduce((x, y) => (x._1 + y._1, x._2 + y._2))
val avg = sum._2 / sum._1출력
data: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
dataRdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[25] at parallelize at <console>:29
sum: (Int, Int) = (10,55)
avg: Int = 5
입력
%spark
val data = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val dataRdd = sc.parallelize(data)
dataRdd.filter(_ > 4).collect()출력
data: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
dataRdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[27] at parallelize at <console>:28
res30: Array[Int] = Array(5, 6, 7, 8, 9, 10)
입력
%spark
val data = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val dataRdd = sc.parallelize(data)
dataRdd.filter(_ <= 8).collect()출력
data: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
dataRdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[29] at parallelize at <console>:28
res31: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8)
입력
%spark
val data1 = Array(1, 2)
val data2 = Array(1, 2, 3)
val dataRdd1 = sc.parallelize(data1)
val dataRdd2 = sc.parallelize(data2)
dataRdd1.union(dataRdd2).collect()출력
data1: Array[Int] = Array(1, 2)
data2: Array[Int] = Array(1, 2, 3)
dataRdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[34] at parallelize at <console>:32
dataRdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[35] at parallelize at <console>:33
res33: Array[Int] = Array(1, 2, 1, 2, 3)
입력
%spark
val data1 = Array(1, 2)
val data2 = Array(1, 2, 3)
val dataRdd1 = sc.parallelize(data1)
val dataRdd2 = sc.parallelize(data2)
dataRdd1.intersection(dataRdd2).collect()출력
data1: Array[Int] = Array(1, 2)
data2: Array[Int] = Array(1, 2, 3)
dataRdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[37] at parallelize at <console>:32
dataRdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[38] at parallelize at <console>:33
res34: Array[Int] = Array(1, 2)
입력
%spark
val data1 = Array(1, 2)
val data2 = Array(1, 2, 3)
val dataRdd1 = sc.parallelize(data1)
val dataRdd2 = sc.parallelize(data2)
dataRdd1.subtract(dataRdd2).collect()출력
data1: Array[Int] = Array(1, 2)
data2: Array[Int] = Array(1, 2, 3)
dataRdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[45] at parallelize at <console>:32
dataRdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[46] at parallelize at <console>:33
res35: Array[Int] = Array()
입력
%spark
val data1 = Array(1, 2)
val data2 = Array(1, 2, 3)
val dataRdd1 = sc.parallelize(data1)
val dataRdd2 = sc.parallelize(data2)
dataRdd2.subtract(dataRdd1).collect()출력
data1: Array[Int] = Array(1, 2)
data2: Array[Int] = Array(1, 2, 3)
dataRdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[51] at parallelize at <console>:32
dataRdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[52] at parallelize at <console>:33
res36: Array[Int] = Array(3)
입력
%spark
val data1 = Array(1, 2)
val data2 = Array(1, 2, 3)
val dataRdd1 = sc.parallelize(data1)
val dataRdd2 = sc.parallelize(data2)
dataRdd1.cartesian(dataRdd2).collect()출력
data1: Array[Int] = Array(1, 2)
data2: Array[Int] = Array(1, 2, 3)
dataRdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[57] at parallelize at <console>:32
dataRdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[58] at parallelize at <console>:33
res37: Array[(Int, Int)] = Array((1,1), (1,2), (1,3), (2,1), (2,2), (2,3))
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] pyspark는 코드 상에서 2개 이상의 rdd를 같은 위치에 파일을 저장할 수 없다. (0) | 2022.05.28 |
|---|---|
| [Spark] org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory file (0) | 2022.05.28 |
| [Spark] Zeppelin 실행시 초기 로그 확인하기 (0) | 2022.04.15 |
| [Spark] Apache Zeppelin 로그 파일 위치 확인하기 (0) | 2022.04.15 |
| [Spark] Apache Spark + Apache Zeppelin 실행하기 (0) | 2022.04.15 |