
스파크 테스트 중 다음과 같은 에러가 발생
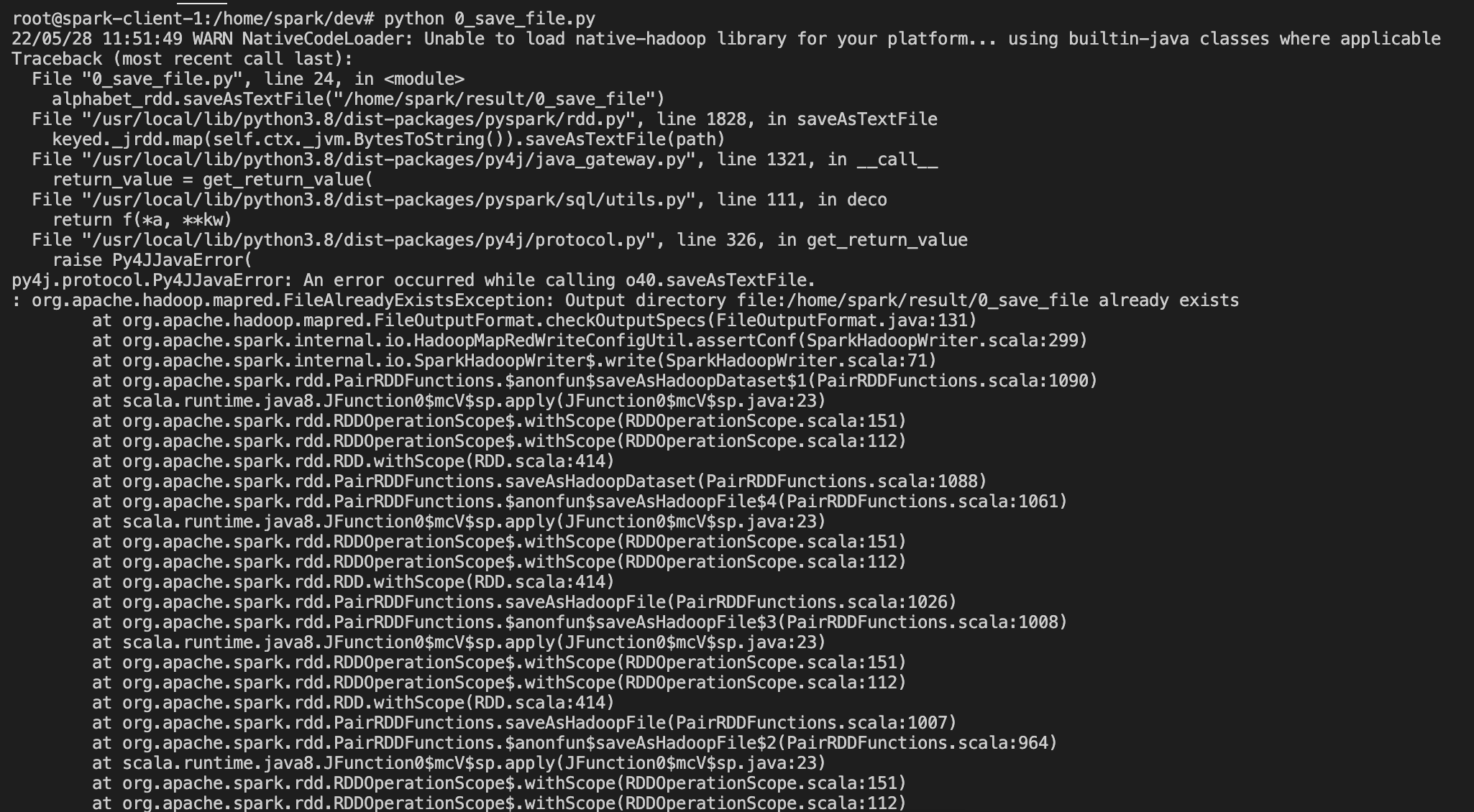

22/05/28 11:51:49 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Traceback (most recent call last):
File "0_save_file.py", line 24, in <module>
alphabet_rdd.saveAsTextFile("/home/spark/result/0_save_file")
File "/usr/local/lib/python3.8/dist-packages/pyspark/rdd.py", line 1828, in saveAsTextFile
keyed._jrdd.map(self.ctx._jvm.BytesToString()).saveAsTextFile(path)
File "/usr/local/lib/python3.8/dist-packages/py4j/java_gateway.py", line 1321, in __call__
return_value = get_return_value(
File "/usr/local/lib/python3.8/dist-packages/pyspark/sql/utils.py", line 111, in deco
return f(*a, **kw)
File "/usr/local/lib/python3.8/dist-packages/py4j/protocol.py", line 326, in get_return_value
raise Py4JJavaError(
py4j.protocol.Py4JJavaError: An error occurred while calling o40.saveAsTextFile.
: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory file:/home/spark/result/0_save_file already exists
at org.apache.hadoop.mapred.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:131)
at org.apache.spark.internal.io.HadoopMapRedWriteConfigUtil.assertConf(SparkHadoopWriter.scala:299)
at org.apache.spark.internal.io.SparkHadoopWriter$.write(SparkHadoopWriter.scala:71)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsHadoopDataset$1(PairRDDFunctions.scala:1090)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:414)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopDataset(PairRDDFunctions.scala:1088)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsHadoopFile$4(PairRDDFunctions.scala:1061)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:414)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:1026)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsHadoopFile$3(PairRDDFunctions.scala:1008)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:414)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:1007)
at org.apache.spark.rdd.PairRDDFunctions.$anonfun$saveAsHadoopFile$2(PairRDDFunctions.scala:964)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:414)
at org.apache.spark.rdd.PairRDDFunctions.saveAsHadoopFile(PairRDDFunctions.scala:962)
at org.apache.spark.rdd.RDD.$anonfun$saveAsTextFile$2(RDD.scala:1578)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:414)
at org.apache.spark.rdd.RDD.saveAsTextFile(RDD.scala:1578)
at org.apache.spark.rdd.RDD.$anonfun$saveAsTextFile$1(RDD.scala:1564)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:414)
at org.apache.spark.rdd.RDD.saveAsTextFile(RDD.scala:1564)
at org.apache.spark.api.java.JavaRDDLike.saveAsTextFile(JavaRDDLike.scala:551)
at org.apache.spark.api.java.JavaRDDLike.saveAsTextFile$(JavaRDDLike.scala:550)
at org.apache.spark.api.java.AbstractJavaRDDLike.saveAsTextFile(JavaRDDLike.scala:45)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.lang.Thread.run(Thread.java:748)
문제는 생각보다 간단하다.
내 코드를 보면
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("0_save_file")\
.getOrCreate()
alphabet_list = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p',
'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
alphabet_rdd = spark.sparkContext.parallelize(alphabet_list)
alphabet_rdd.saveAsTextFile("/home/spark/result/0_save_file")
spark.stop()
마지막에 rdd를 저장하는데,
기존에 폴더가 있어서 문제가 됐다.

기존 폴더를 지우고 실행하면 정상동작한다.

'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] 리스트 값이 있는 rdd 여러개를 하나의 rdd로 만드는 방법 (0) | 2022.05.28 |
|---|---|
| [Spark] pyspark는 코드 상에서 2개 이상의 rdd를 같은 위치에 파일을 저장할 수 없다. (0) | 2022.05.28 |
| [Spark] Zeppelin 사용하여 여러가지 RDD 만드는 방법 parallelize 사용 (0) | 2022.04.15 |
| [Spark] Zeppelin 실행시 초기 로그 확인하기 (0) | 2022.04.15 |
| [Spark] Apache Zeppelin 로그 파일 위치 확인하기 (0) | 2022.04.15 |