
스파크 실행
제플린 실행

간단한 스칼라 코드 입력
val data = sc.parallelize(1 to 100 by 10)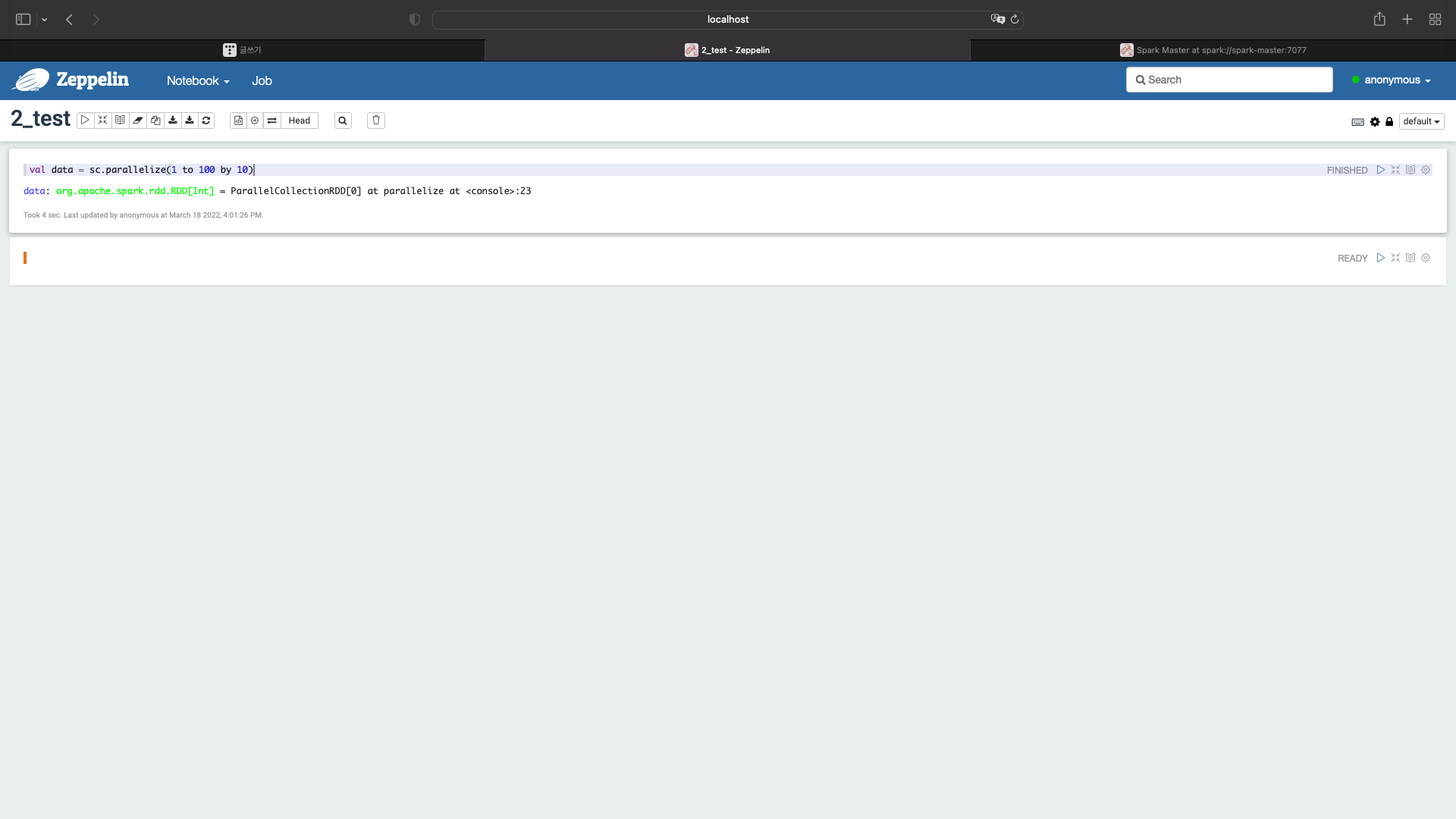
스파크 확인
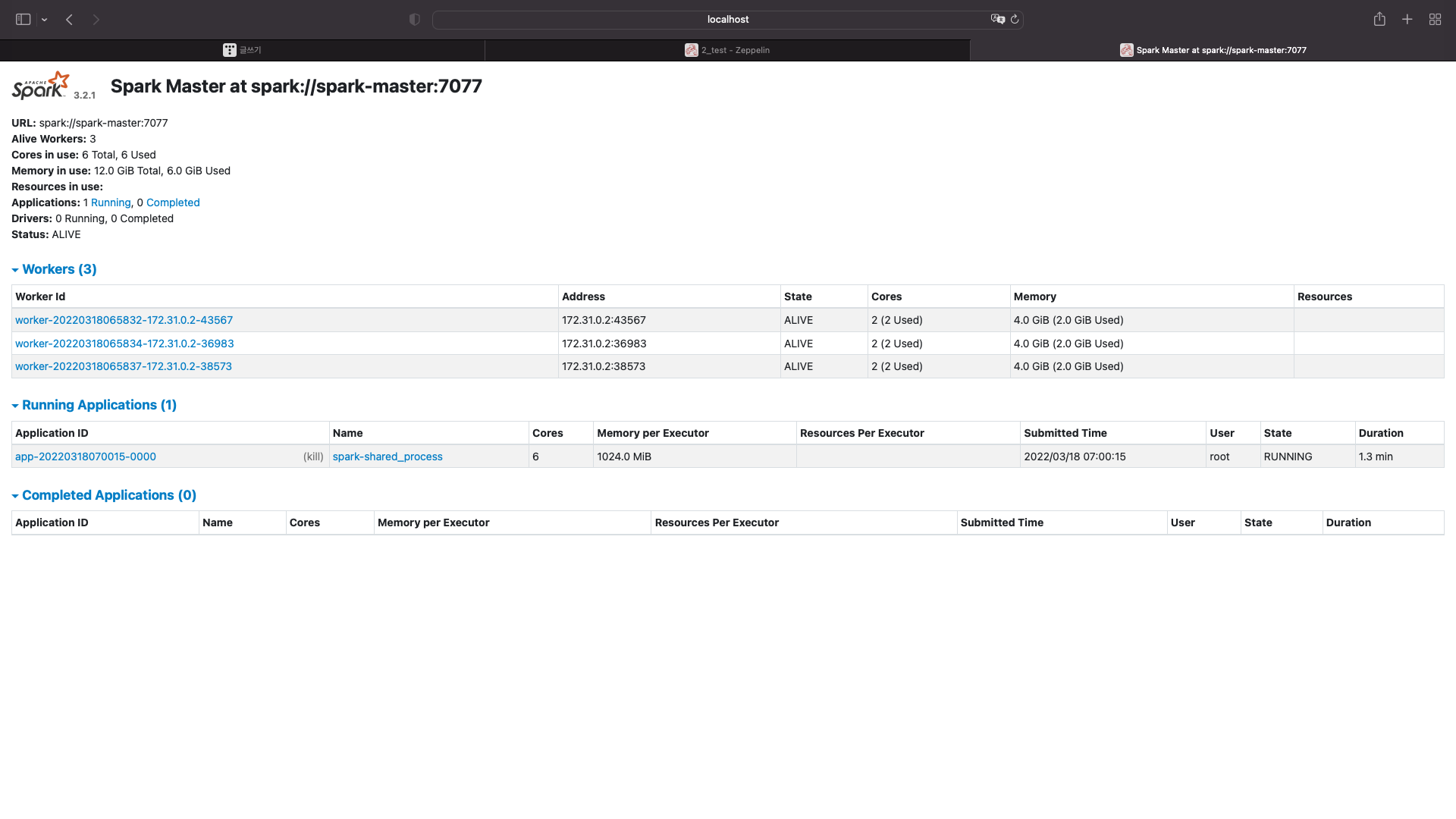
애플리케이션이 자동으로 실행된 것을 확인할 수 있다.
이번에는 저 어플리케이션 아이디를 클릭해보자
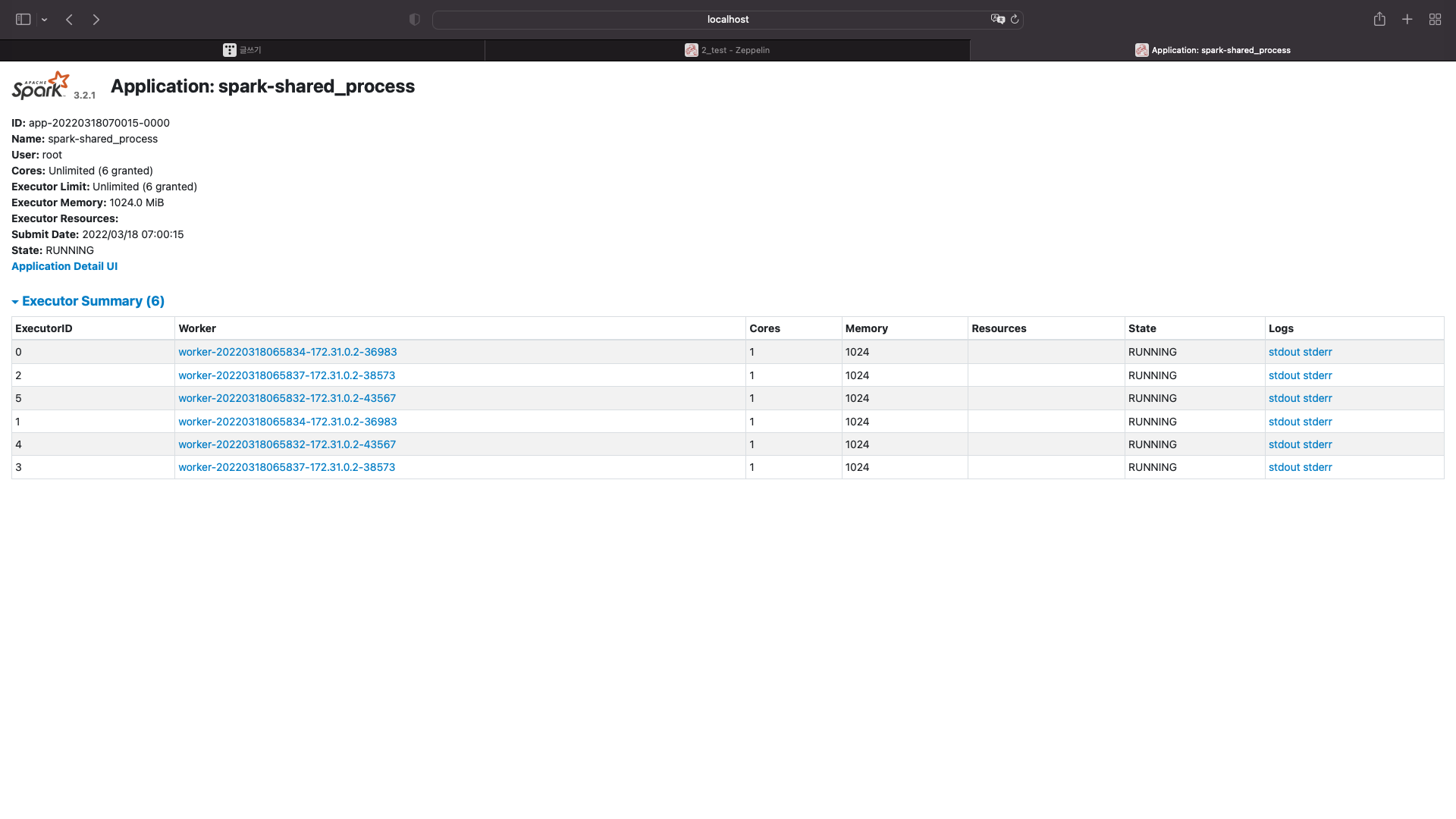
현재 워커노드는 총 3개 있다
총 코어는 6개고 메모리는 12기가이다.
노드마다 코어는 2개씩 갖고있고, 메모리는 4기가씩 갖고있다.
이 어플리케이션은 6개의 코어를 사용하고 코어마다 1기가의 메모리를 사용한다는 것을 알 수있다
이번엔 스파크를 액션시켜보자
data.count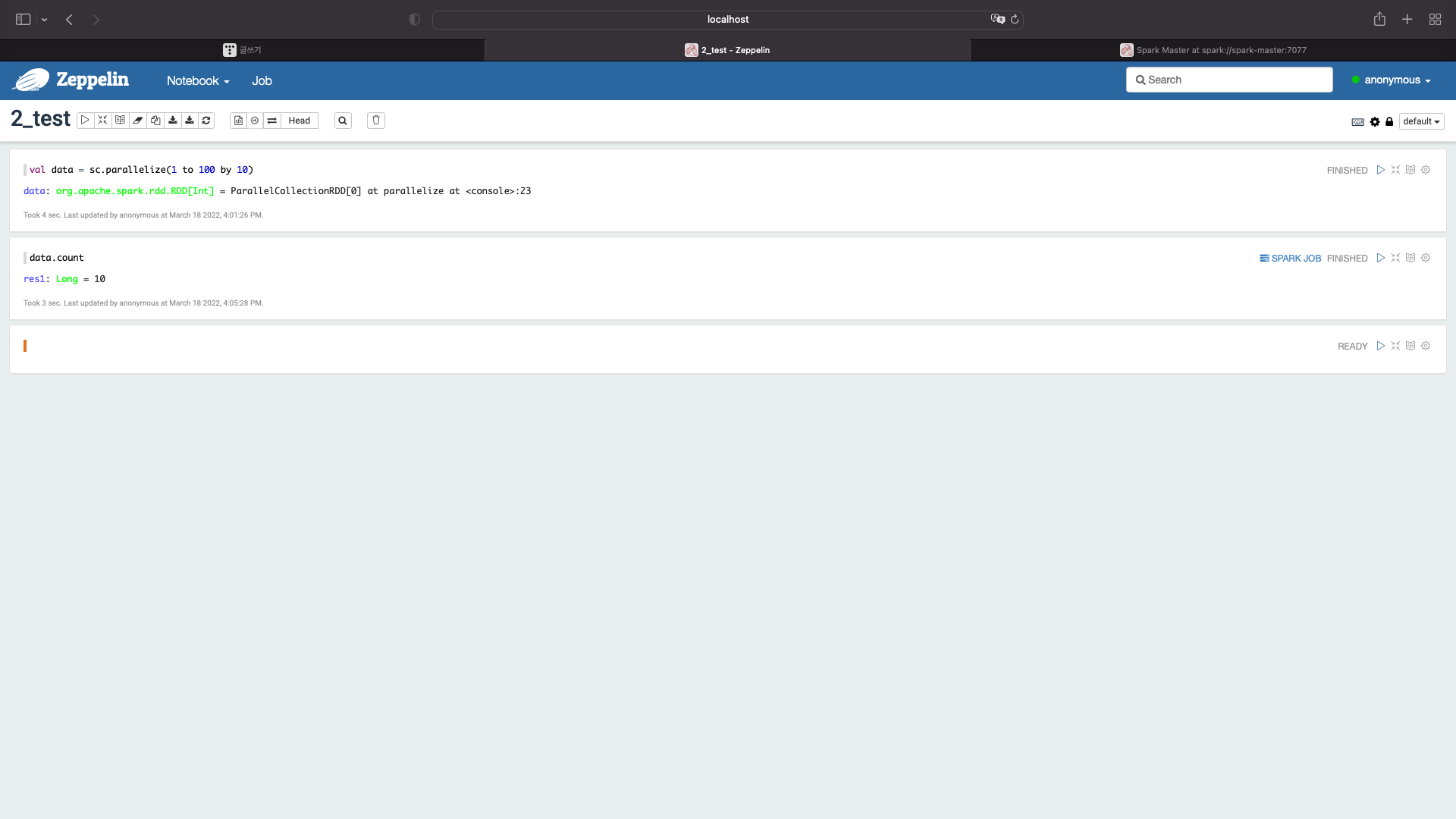
스파크 메인화면을 보자
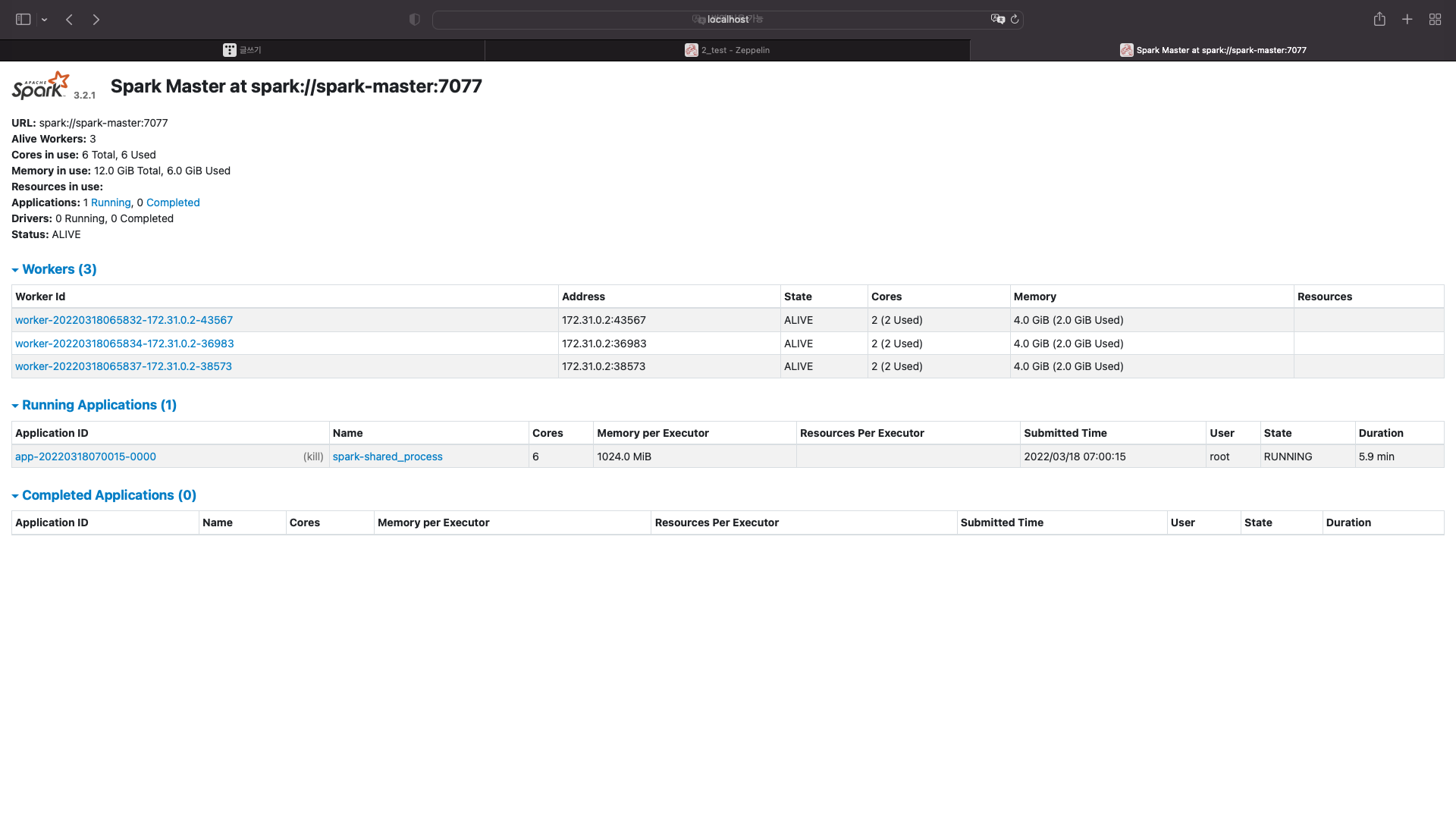
스파크 메인화면에서는 어플리케이션에 대한 정보만 확인할 수 있다.
어플리케이션 아이디를 다시 클릭해보자
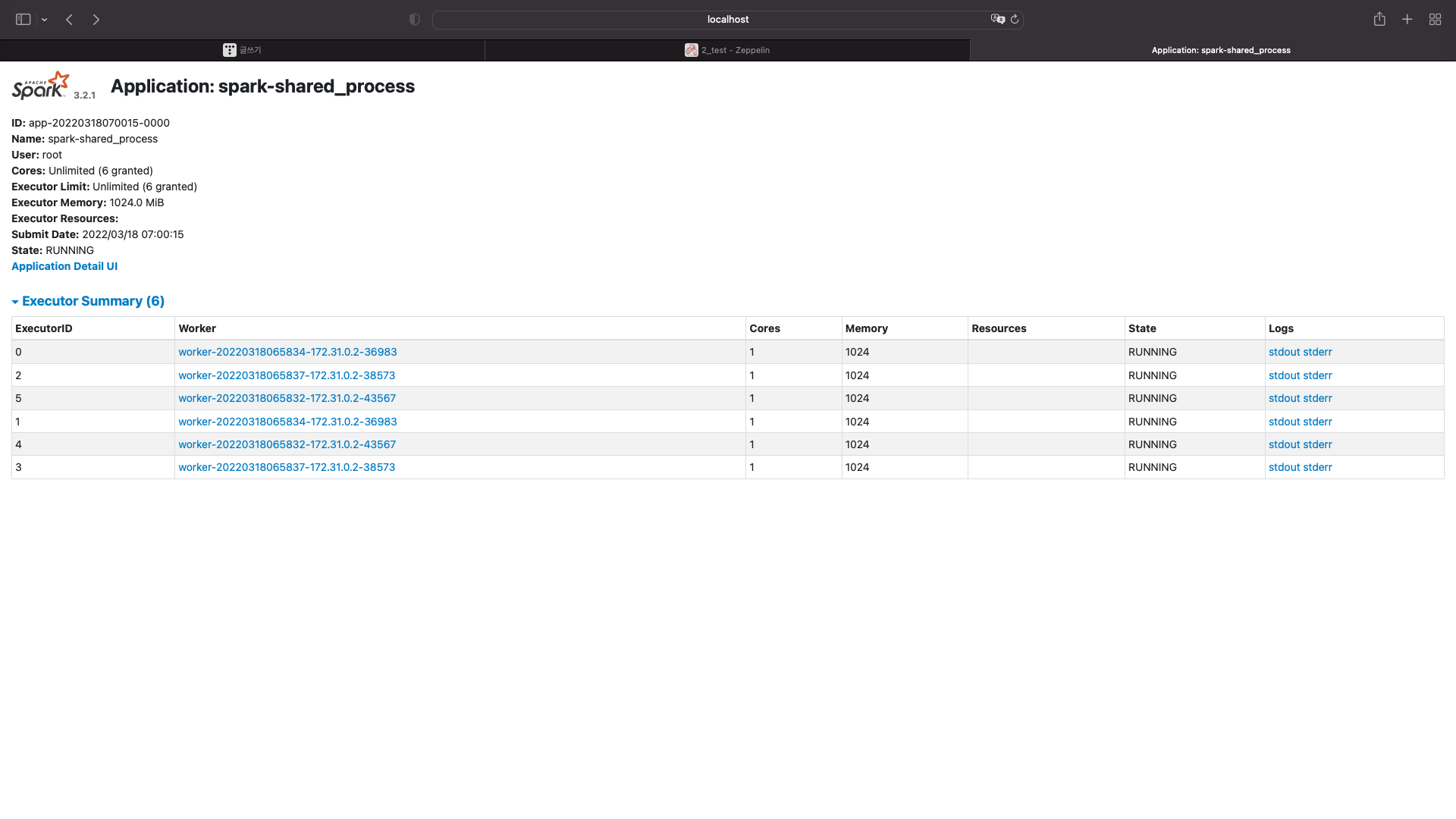
여기에서는 각각의 노드가 몇코어씩, 그리고 코어마다 메모리 몇기가를 사용하는지만 알 수있다.
실행결과를 확인하려면 localhost:4040으로 들어가야한다
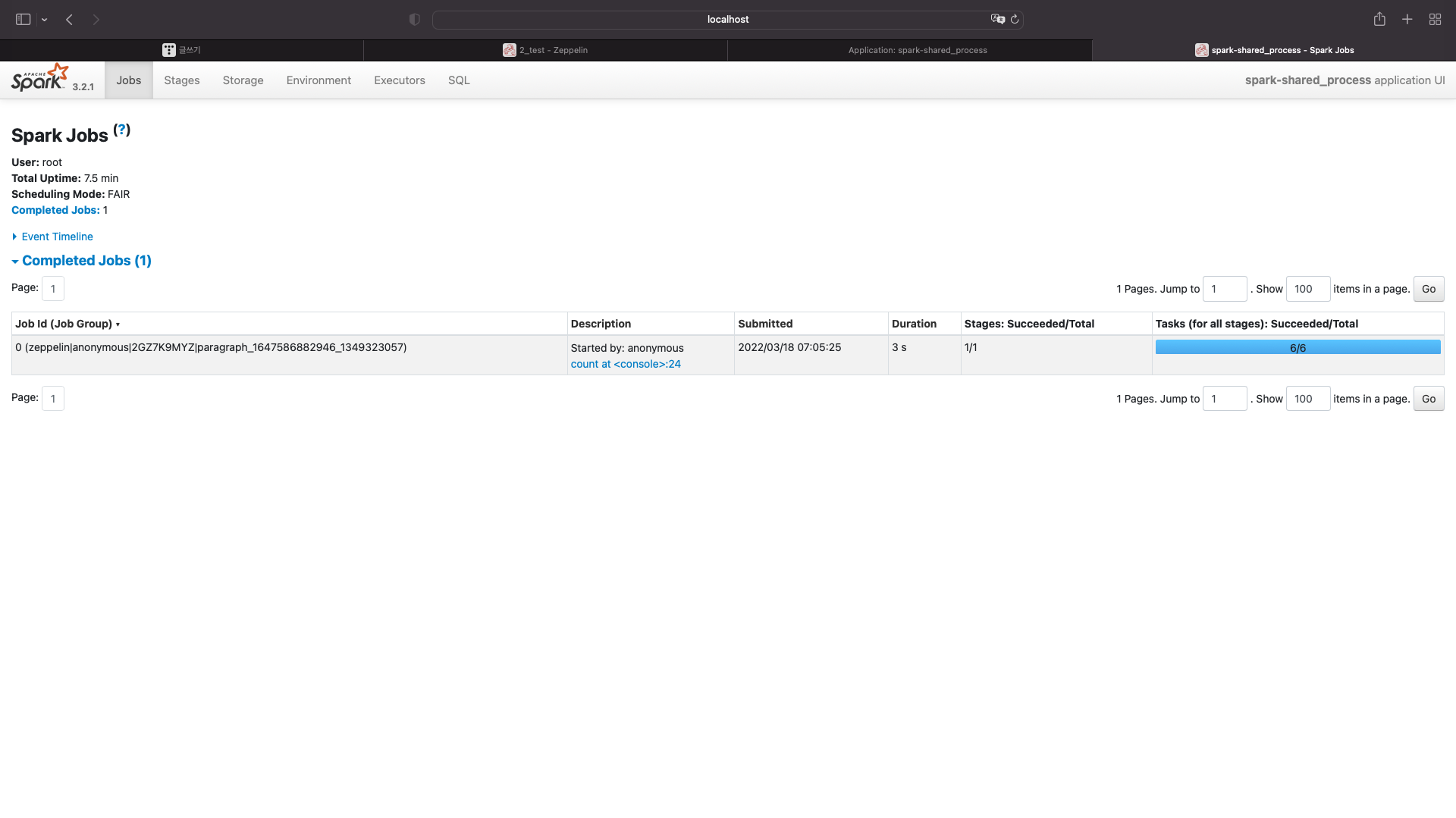
방금 실행한 잡이 보여진다.
다시한번 제플린에서 실행해보자
data.count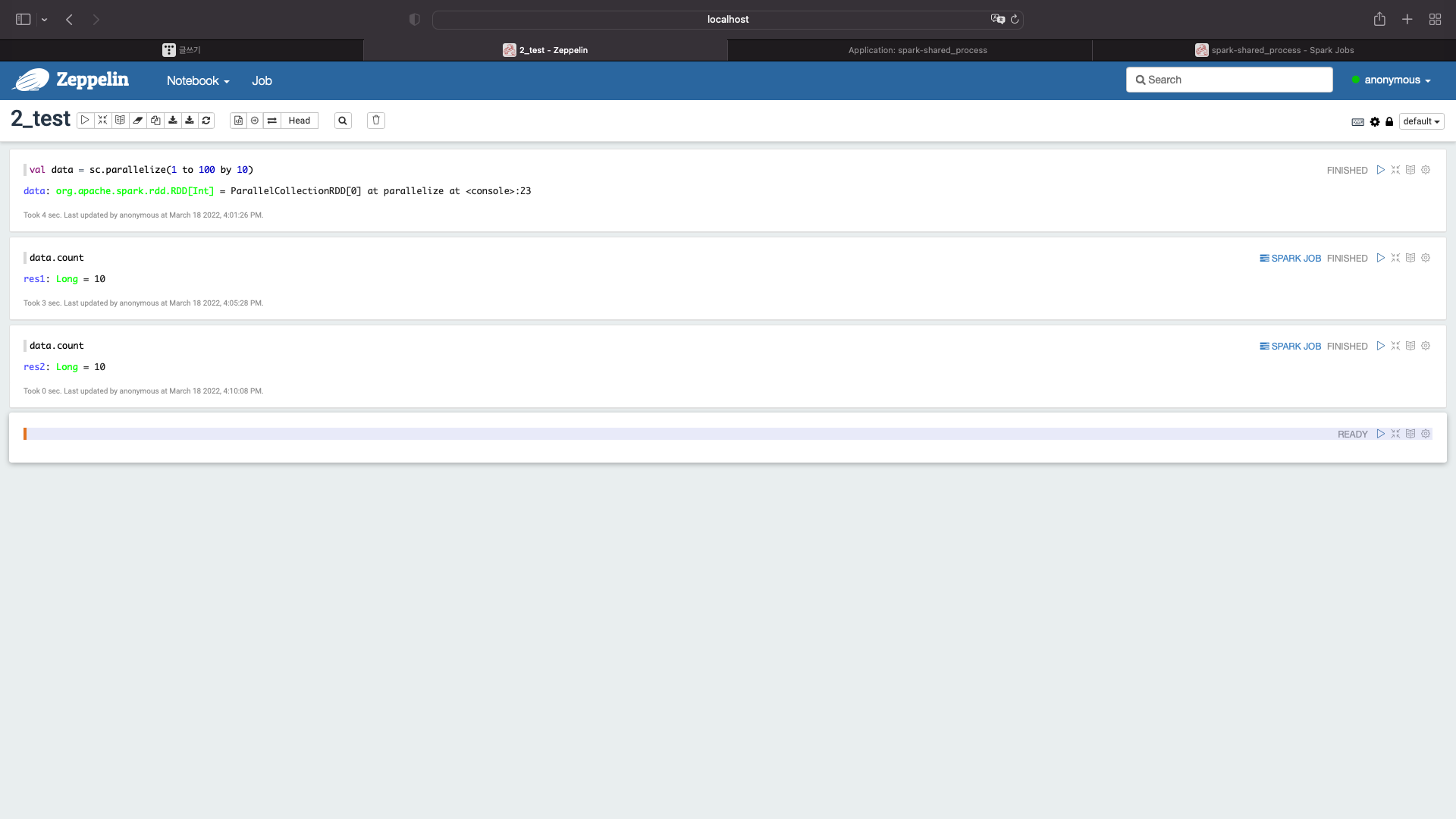
localhost:4040을 보자
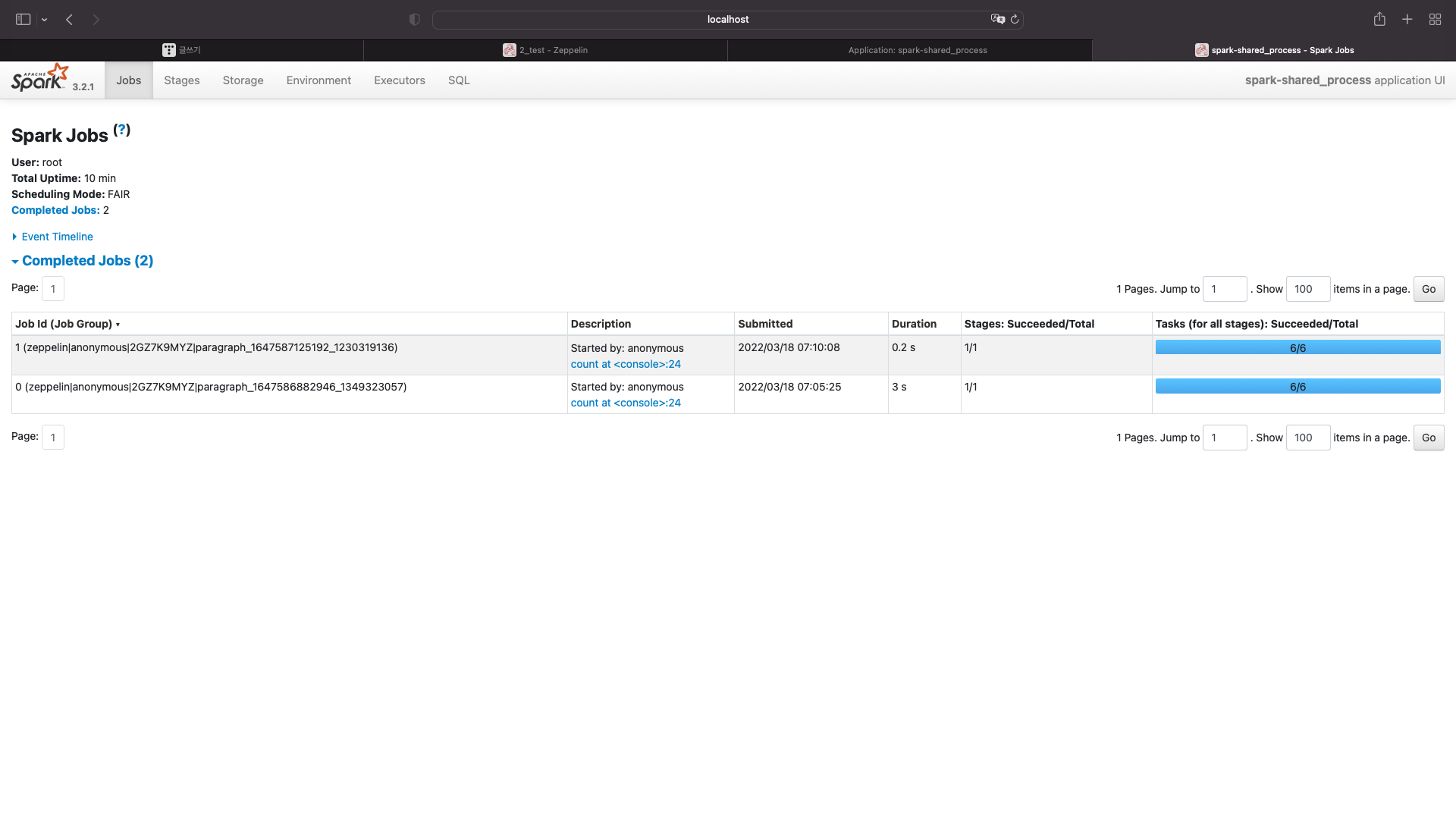
잡이 하나 더 늘었다
이번에는 처음에 친 코드와 비슷한 코드를 입력해보자
val data_test = sc.parallelize(1 to 100 by 10)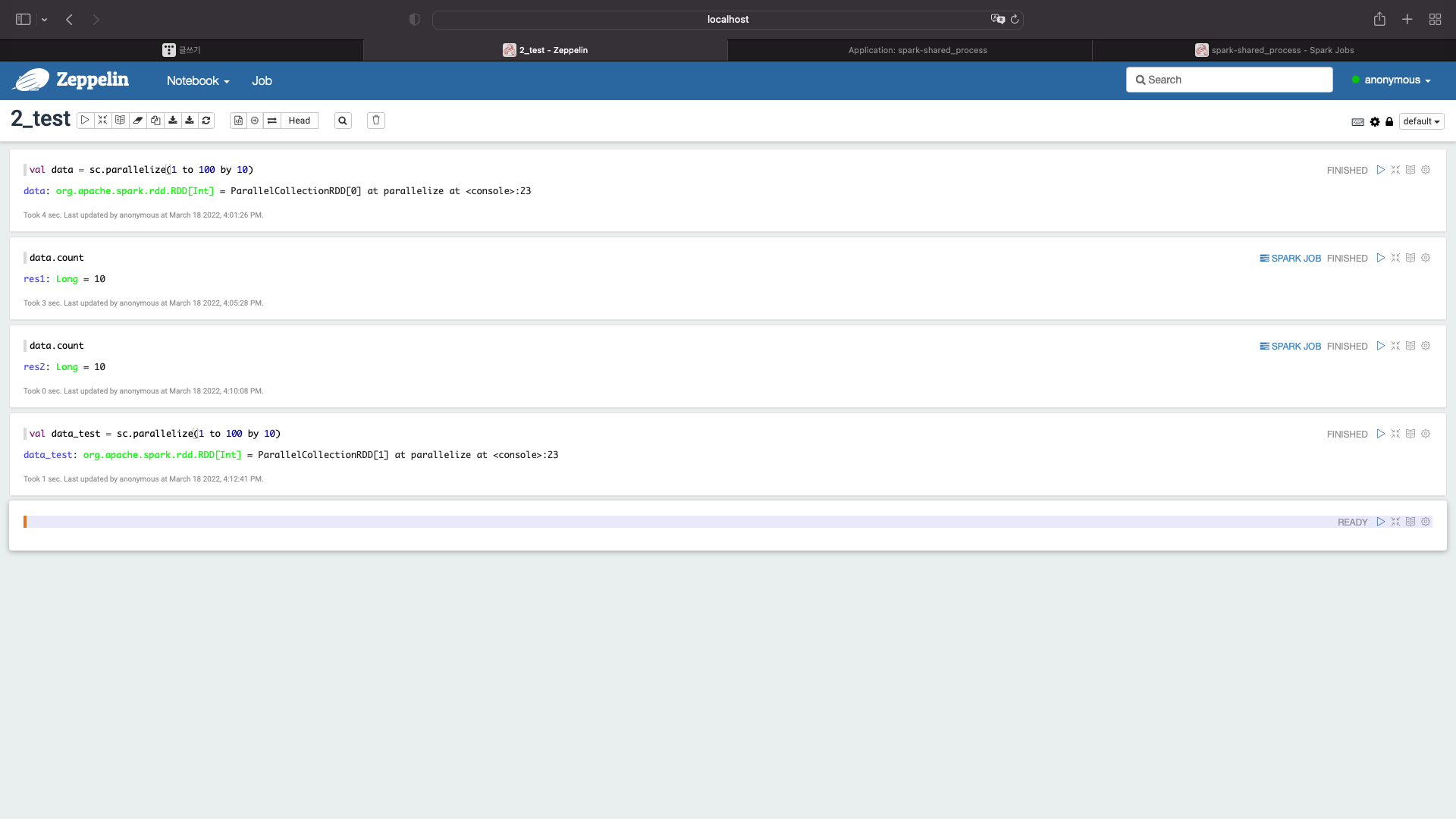
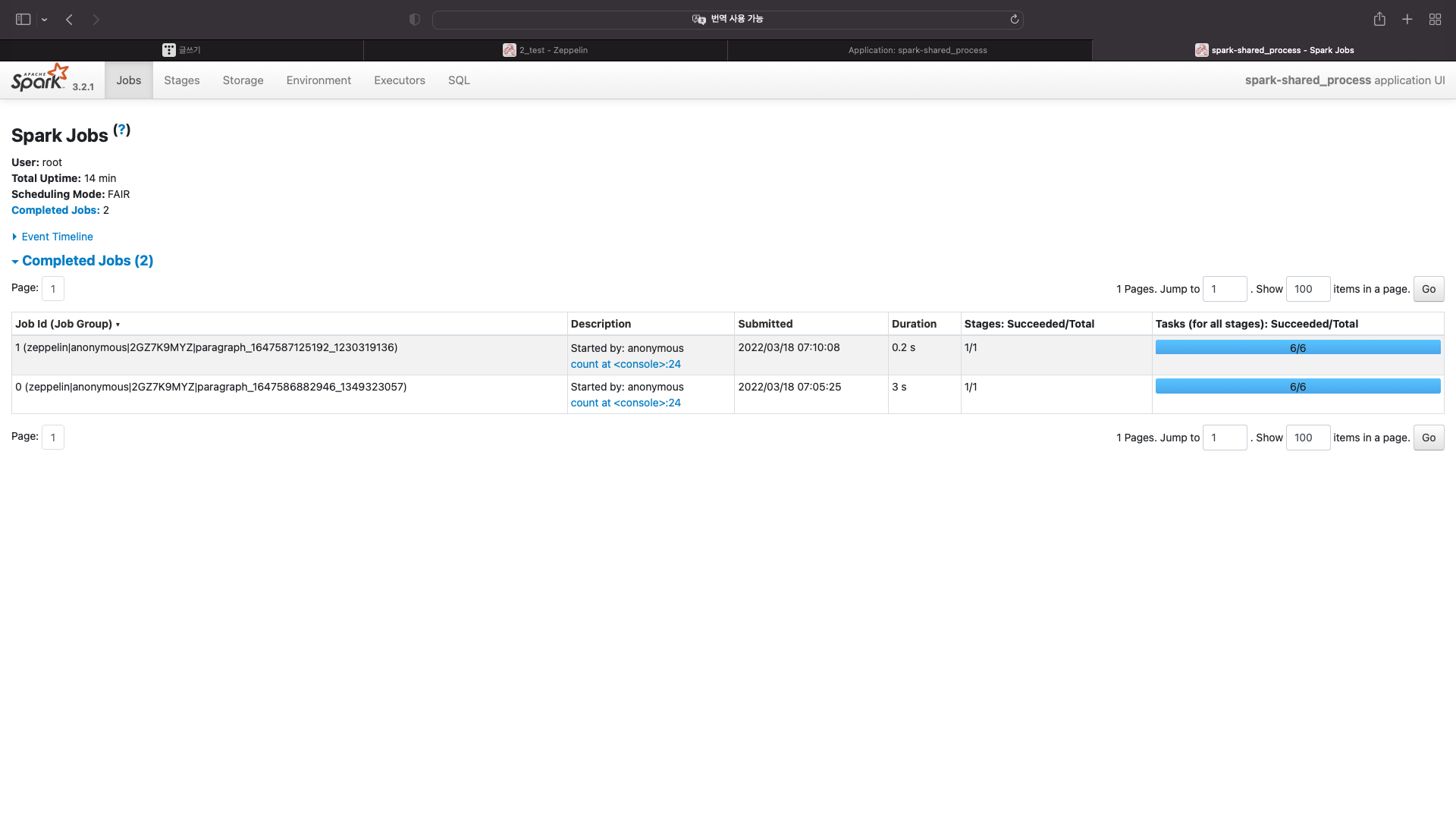
localhost:4040 을 확인해보자
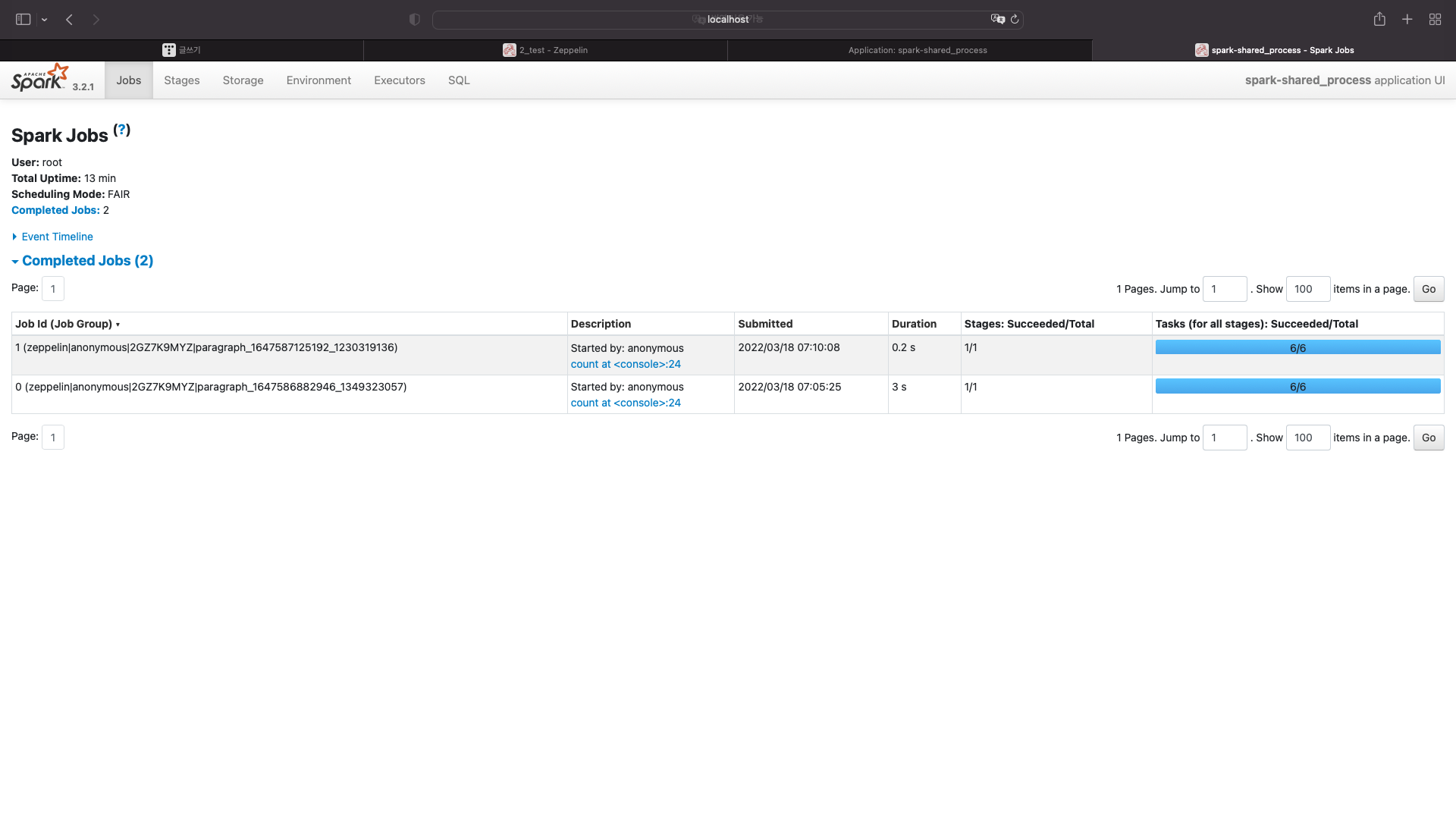
잡이 실행되지 않았다.
다시한번 확인해보자
sc.parallelize(1 to 100 by 10)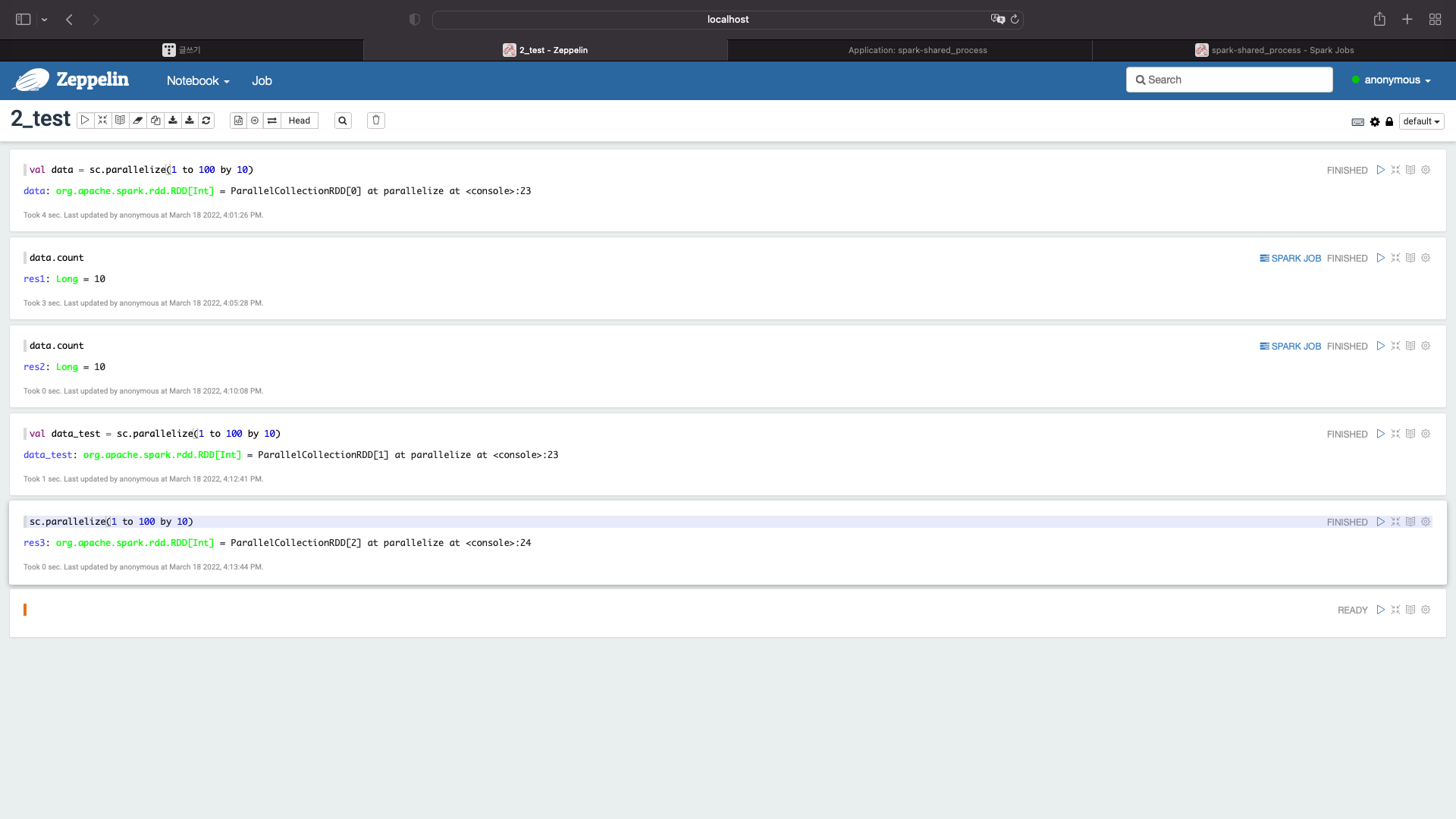
localhost:4040
스파크를 이용할때 내장함수 중 트랜스포머와 액션이라는 종류가 있는데,
스파크는 액션일 때 실행되는 것을 알 수 있다.
이번에는 액션관련 함수를 사용해서 실행시켜보자
data_test.take(5)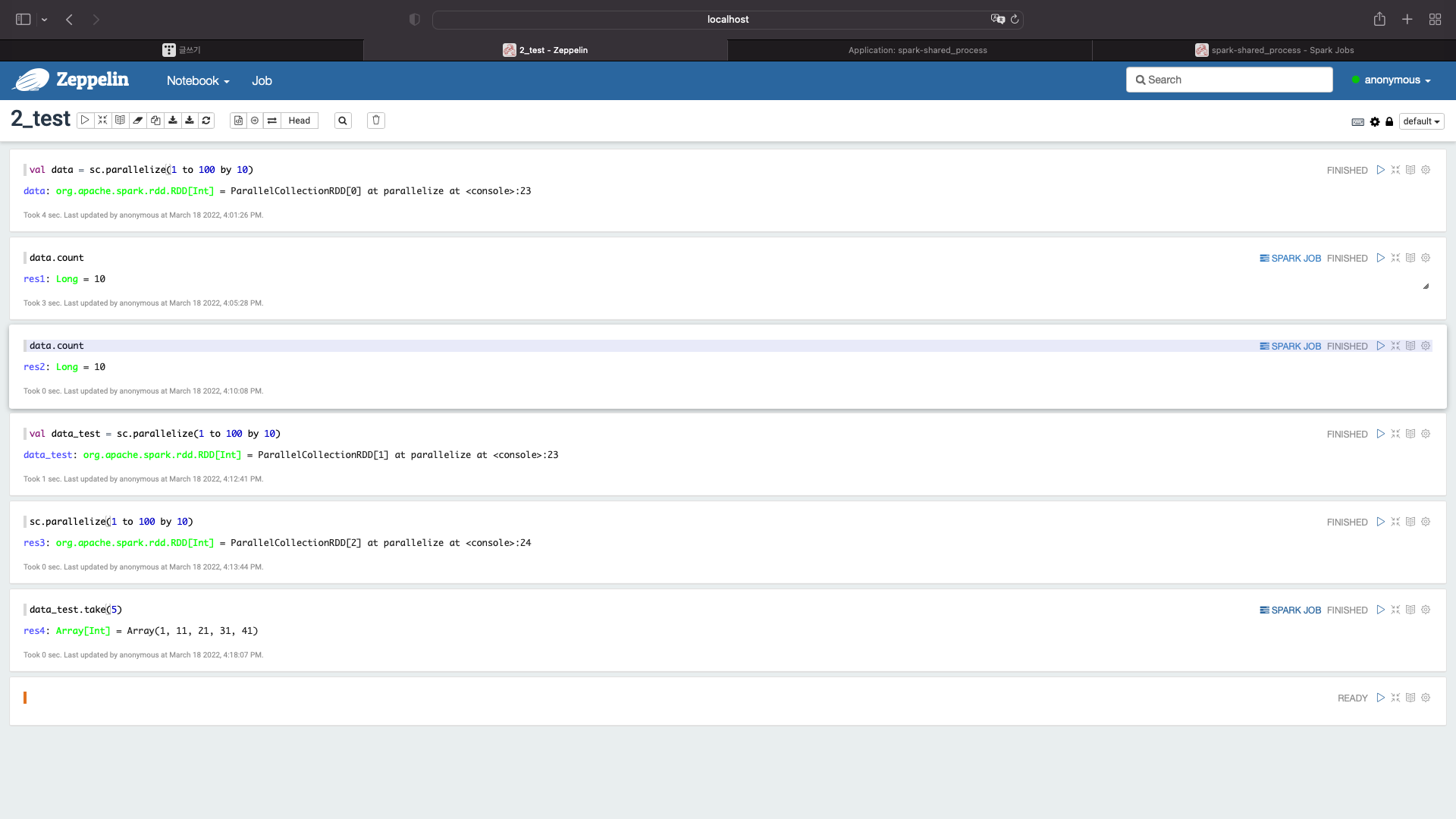
localhost:4040
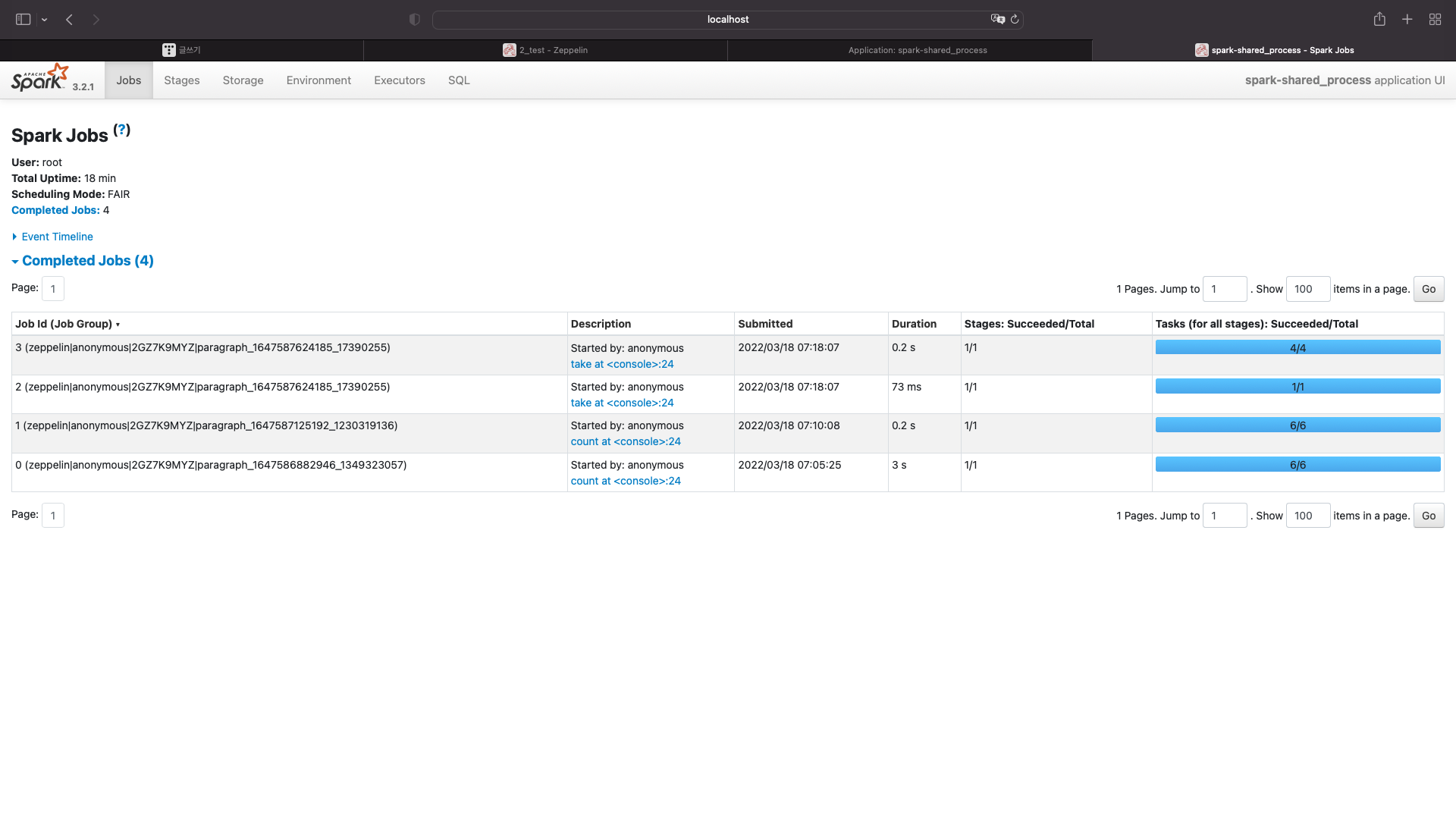
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] 제플린에서 spark-shell 옵션 설정하는 방법 (0) | 2022.03.19 |
|---|---|
| [Spark] 아파치 스파크 클러스터와 제플린 실행시 jps 상태 확인 (0) | 2022.03.19 |
| [Spark] spark stand alone cluster, zeppline 사용시 jps, jdk 상태 (0) | 2022.03.18 |
| [Spark] zeppelin에서 spark 어플리케이션 실행하고 종료하는 방법 (0) | 2022.03.18 |
| [Spark] spark cluster에서 워커노드별 코어와 메모리 할당 (0) | 2022.03.18 |
스파크 실행
제플린 실행
간단한 스칼라 코드 입력
val data = sc.parallelize(1 to 100 by 10)
스파크 확인
애플리케이션이 자동으로 실행된 것을 확인할 수 있다.
이번에는 저 어플리케이션 아이디를 클릭해보자
현재 워커노드는 총 3개 있다
총 코어는 6개고 메모리는 12기가이다.
노드마다 코어는 2개씩 갖고있고, 메모리는 4기가씩 갖고있다.
이 어플리케이션은 6개의 코어를 사용하고 코어마다 1기가의 메모리를 사용한다는 것을 알 수있다
이번엔 스파크를 액션시켜보자
data.count
스파크 메인화면을 보자
스파크 메인화면에서는 어플리케이션에 대한 정보만 확인할 수 있다.
어플리케이션 아이디를 다시 클릭해보자
여기에서는 각각의 노드가 몇코어씩, 그리고 코어마다 메모리 몇기가를 사용하는지만 알 수있다.
실행결과를 확인하려면 localhost:4040으로 들어가야한다
방금 실행한 잡이 보여진다.
다시한번 제플린에서 실행해보자
data.count
localhost:4040을 보자
잡이 하나 더 늘었다
이번에는 처음에 친 코드와 비슷한 코드를 입력해보자
val data_test = sc.parallelize(1 to 100 by 10)
localhost:4040 을 확인해보자
잡이 실행되지 않았다.
다시한번 확인해보자
sc.parallelize(1 to 100 by 10)
localhost:4040
스파크를 이용할때 내장함수 중 트랜스포머와 액션이라는 종류가 있는데,
스파크는 액션일 때 실행되는 것을 알 수 있다.
이번에는 액션관련 함수를 사용해서 실행시켜보자
data_test.take(5)
localhost:4040
'Data Engineering > Spark' 카테고리의 다른 글
| [Spark] 제플린에서 spark-shell 옵션 설정하는 방법 (0) | 2022.03.19 |
|---|---|
| [Spark] 아파치 스파크 클러스터와 제플린 실행시 jps 상태 확인 (0) | 2022.03.19 |
| [Spark] spark stand alone cluster, zeppline 사용시 jps, jdk 상태 (0) | 2022.03.18 |
| [Spark] zeppelin에서 spark 어플리케이션 실행하고 종료하는 방법 (0) | 2022.03.18 |
| [Spark] spark cluster에서 워커노드별 코어와 메모리 할당 (0) | 2022.03.18 |